
【论文】略读笔记5-前沿-DRL异构计算适配

📖《A Framework for Mapping DRL Algorithms With Prioritized Replay Buffer Onto Heterogeneous Platforms》
🎯需求
- 尽管深度强化学习(DRL)最近在自动驾驶汽车、机器人和监控中取得了成功,但训练DRL代理需要大量的时间和计算资源。
- 在 RL 中,代理与环境迭代交互以改进其策略,以便最大化沿轨迹的预期累积奖励。该策略在类 RL 中表示为查找表,而在深度强化学习 (DRL) 中表示为神经网络。
- 训练DRL代理非常耗时,因为它需要通过与环境交互和梯度更新来更新表示为神经网络的策略来收敛(例如,AlphaGo)。
- 最先进的并行DRL框架采用由并行执行者、集中式学习器和优先级经验回放池(Prioritized Replay Buffer)组成的通用架构,如图1(a)所示。
- 并行执行者同时从环境中收集数据,并将数据插入到优先级经验回放池中。
- 集中式学习器从优先经验回放池中采样数据,并执行随机梯度下降 (SGD)以更新策略。
- 学习后的新优先级由优先级经验回放池更新。每个数据点的优先级与损失函数成正比,采样分布与优先级成正比。缓冲区中每个数据点的优先级存储在 K-ary Sum 树数据结构,可以在O(logN)时间复杂度内完成,其中N是经验回放池中的数据点总数。

图1
- 具有优先级经验回放池的 DRL 的计算基元包括环境仿真、神经网络推理、从优先级经验回放池采样、更新优先级经验回放池和神经网络训练。运行这些基元的速度因各种 DRL 算法(如深度 Q 网络和深度确定性策略梯度)而异。这使得 DRL 算法的固定映射效率低下。
- 由 CPU、FPGA 和 GPU 组成的异构平台有望加速DRL算法。这是因为运行关键 DRL 基元的速度在不同的 DRL 算法之间有很大差异。例如,
- 在 FPGA 上训练小尺寸神经网络比在 CPU 和 GPU 上训练更快,而在 GPU 上训练大尺寸神经网络比在 CPU 和 FPGA 上训练更快。
- 小批量采样在 FPGA 上比在 CPU 和 GPU 上更快,而大批量采样在 GPU 上比在 CPU 和 FPGA 上更快。

🚧现状
- 最近的一些工作集中在DRL算法的硬件加速上。
- 之前的工作要么专注于开发没有硬件加速细节的DRL算法的并行范式,要么仅限于特定的DRL算法加速。
- 此外,现有的工作都没有有效地支持内存绑定的原语,如优先重播缓冲区。由于内存瓶颈,这会在这些现有框架实现的吞吐量与同构平台提供的峰值吞吐量之间产生性能差距。
- 在我们之前的工作中,提出了具有优先重放缓冲区的DRL算法到CPU-FPGA异构平台的映射。当优先重放缓冲器和学习器适合FPGA的片上资源时,该设计可实现最先进的训练吞吐量。
- 但是,它无法处理片上资源不足以满足优先重放缓冲区和学习器的情况。
- 为了在更广泛的场景中实现最先进的训练吞吐量,在本文中,我们提出了一个框架,用于将具有优先级重放缓冲区的DRL算法映射到CPU-GPU-FPGA异构平台上,以实现给定DRL算法及其输入参数的卓越训练吞吐量。
🛩创新
- 在这项工作中,我们提出了一个框架,用于将 DRL 算法映射到由多核 CPU、FPGA 和 GPU 组成的异构平台上。
- CPU 适用于复杂控制流的计算;
- GPU 适用于大数据并行计算,
- FPGA 适用于内存访问量大、数据依赖细粒度的计算。
- 我们为 CPU、FPGA 和 GPU 上的每个基元提供了单独的加速器。我们提出了设计空间探索,在给定的DRL算法中选择最佳映射,从而使整体训练吞吐量最大化。此外,我们放宽了优先级更新和在优先级经验回放池中执行的采样之间的数据依赖关系,以完全隐藏 CPU、FPGA 和 GPU 之间数据传输造成的延迟,而不会牺牲使用目标 DRL 算法学习的代理获得的奖励。
- 具体而言,我们的主要贡献是:
- 首先,我们为 CPU、FPGA 和 GPU 上的每个基元开发特定的加速器。
- 其次,我们放宽优先级更新和在优先级经验回放池中执行的采样之间的数据依赖关系。通过这样做,可以完全隐藏 CPU、FPGA 和 GPU 之间数据传输造成的延迟,而不会牺牲使用目标 DRL 算法学习的代理获得的奖励。
- 最后,给定 DRL 算法规范,我们的设计空间探索会根据分析性能模型自动选择各种基元的最佳映射。
- 具体而言,我们的主要贡献是:
- 在 CPU 上,我们利用 OpenMP 在优先经验回放池的采样和优先级更新中利用数据并行性。我们使用 PyTorch 进行神经网络训练。
- 在 GPU 上,我们开发了一个定制的 CUDA 内核,用于基于并行求和缩减的采样和优先级更新。我们使用 PyTorch 和 CuDNN 后端进行神经网络训练。
- 在 FPGA 上,我们开发了一个通用的面向吞吐量的学习模块,该模块利用了神经网络模型并行性和数据并行性。我们为重放管理模块 (RMM) 开发了一个通用加速器模板,该模板利用库并行性并可扩展到大批量大小。我们提议的 RMM 支持并行插入、并行采样和并行优先级更新 K-ary Sum 树。我们通过以下方式优化片上数据访问的性能:
- 专用的可变精度定点数据格式,用于在 RMM 中存储优先级值;
- 分区支持无冲突并行数据访问的 K-ary Sum 树;
- 流水线重放操作,允许并发访问存储 K-ary Sum 树。
- 为了隐藏用于训练的异构加速器之间的数据传输导致的延迟,我们放宽了优先级更新和优先级经验回放池中采样之间的数据依赖关系。我们凭经验表明,在广泛使用的基准环境中,具有和不具有数据依赖性的DRL算法之间经过训练的代理的性能差异可以忽略不计。
- 我们提出了一种设计空间探索和设计自动化工作流程,该工作流程在给定任意DRL算法的情况下,以最佳方式选择每个组件到 CPU-GPU-FPGA 异构系统上的映射。
- 对于广泛使用的DRL算法,包括 DQN 和 DDPG,与基线映射相比,我们的框架生成的映射在训练吞吐量方面表现出高达997.3×的加速。
📊效果
- 在广泛使用的基准环境中,我们的实验结果表明,与同一异构平台上的基线映射相比,训练吞吐量提高了 997.3×。与最先进的分布式强化学习框架RLlib相比,我们实现了 1.06x~ 训练吞吐量提高 1005×。
🧠疑问
1. 什么是优先级经验回放池?
- 当我们使用Q-learning算法进行在线方式学习时,会存在两个问题[2]:
- 1.交互得到的样本序列存在一定相关性(在线学习场景下往往刚得到一个样本就将其用于训练)。而机器学习模型对训练样本的假设是独立、同分布的,上述场景下的样本序列打破了这种独立同分布特性,因此效果不佳。
- 2.交互样本使用的效率过低。因为每次要使用一定的时间获取一个batch的样本才能完成一次训练,所以对样本的获取是有些慢的,且在线学习场景下往往会将学习后的样本直接丢弃,导致利用效率不高。
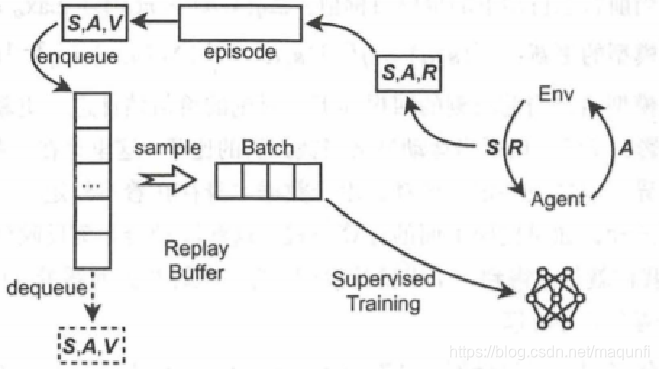
- 因此提出经验回放池结构:用一块有限大小的内存来存储智能体一段时间内和环境交互得
到的经验(元组),每次神经网络需要输入时,会从经验回放池中随机选择一个大小为 minibatch 的经验样本。但是,由于使用随机选择方法,有价值的经验和一般的经验会被以同样的频率回放,可能导致学习效率有限,因此最新研究提出使用基于优先级的经验回放机制。[3]。 经验回放池示意图
2. FPGA是如何使用的?先自行编码成固定的逻辑,再作为通用组件使用?
🗺参考文献
- 标题: 【论文】略读笔记5-前沿-DRL异构计算适配
- 作者: Fre5h1nd
- 创建于 : 2023-05-25 09:02:22
- 更新于 : 2025-06-30 12:14:36
- 链接: https://freshwlnd.github.io/2023/05/25/literature/literatureNotes5/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。



评论