
【论文】略读笔记78-前沿-Meta跨地域ML训练MAST

📖《MAST: Global Scheduling of ML Training across Geo-Distributed Datacenters at Hyperscale》
2024 年 Meta、The Ohio State University团队 发表于 CCF-A 类会议 OSDI。
系列博客:
🎯需求:供需不均衡
- 任务:机器学习应用程序的成功导致机器学习训练成为增长最快的数据中心工作负载。
- 资源:公共云提供商在多个地理分布式数据中心区域运行 ML 训练工作负载,以确保足够的容量。
- 问题:在公有云中,用户必须手动选择数据中心区域来上传机器学习训练数据,并在同一区域启动机器学习训练工作负载,以确保数据和计算共置。不幸的是,个人用户的孤立决策可能会导致跨区域的工作负载需求和硬件供应之间的不匹配,从而损害云提供商的硬件利用率和盈利能力。
- 例如,一个区域可能会耗尽其容量,积累一长串待处理的作业,而另一个区域则有剩余容量闲置。
- Meta 的私有云曾经经历过这种负载不平衡的情况。它由数十个数据中心区域、数百万台机器和数万个 GPU 组成。与公共云类似,用户最初必须手动选择区域来存储训练数据和启动工作负载。
🚧现状
- 虽然在单个集群中调度 ML 工作负载方面已经进行了大量研究,但几乎没有采取任何措施来解决工作负载需求和硬件供应之间的区域不匹配问题。
- 为了提供全局调度抽象,面临两大挑战:
- 1)数据-GPU 共置:如果没有仔细协调,GPU 和数据之间存在位置不匹配的风险。
- 例如,一个区域可能拥有必要的训练数据,但耗尽了可用的 GPU,而另一区域可能拥有可用的 GPU,但缺乏所需的训练数据。由于训练数据量巨大,而跨区域网络带宽有限,按需跨区域数据迁移成本高昂且耗时。
- 2)可扩展性:MAST 不仅分配 GPU 机器进行训练,还分配 CPU 机器进行数据预处理。由于 CPU 机器可以根据需求在 ML 和非 ML 工作负载之间动态重新分配,因此从概念上讲,MAST 需要从分布在数十个区域的数百万台机器中找到运行 ML 工作负载的机器。此前尚未研究过如此规模的全球资源分配。
- 1)数据-GPU 共置:如果没有仔细协调,GPU 和数据之间存在位置不匹配的风险。
🛩创新
- 为了解决 Meta 超大规模私有云中的这个问题,我们为所有机器学习训练工作负载提供了全局调度抽象,使用户免受区域复杂性的影响。用户只需将训练工作负载提交给我们名为 MAST(ML Application Scheduler on Twine 的缩写)的全局调度程序,并依靠它智能地将数据和训练工作负载放置到不同的区域。
- 我们描述了三个设计原则,使 MAST 能够在全球范围内安排复杂的 ML 训练工作负载:时间解耦、范围解耦和穷举搜索。
- 1)时间解耦。我们将调度职责分为两条路径:实时作业调度的快速路径和在后台不断优化数据和机器分配的慢速路径。
- 慢速路径智能地跨区域复制 ML 训练数据,使快速路径能够更轻松地将计算与数据并置。尽管时间安排宽松,但跨区域数据放置仍然非常具有挑战性。
- 它需要持续优化数十亿个数据分区在数十个地理分布式区域的放置,考虑每个区域的容量限制以及来自 Spark 和 Presto 的数百万个日常 ML 训练作业和分析作业的数据访问模式。
- 我们将数据放置建模为混合整数规划 (MIP) 问题,GPU 的稀缺性推动了我们解决方案中的新颖决策。
- 由于 GPU 的成本和需求较高,我们的目标是最大化 GPU 利用率(Utilization)。
- 在 MIP 问题中施加硬性约束,即每个区域的 GPU 需求必须低于 GPU 供应,就像之前针对 CPU 和存储的工作一样,通常会导致问题无法解决。
- 相反,MAST 允许 GPU 超额订阅并根据需要抢占低优先级作业。
- 这种方法要求重新评估 MIP 问题中的目标函数和约束,不仅针对与 GPU 相关的术语,还针对 GPU 依赖的其他资源。我们分享通过生产经验改进 MIP 问题的多次迭代所获得的见解。
- 由于 GPU 的成本和需求较高,我们的目标是最大化 GPU 利用率(Utilization)。
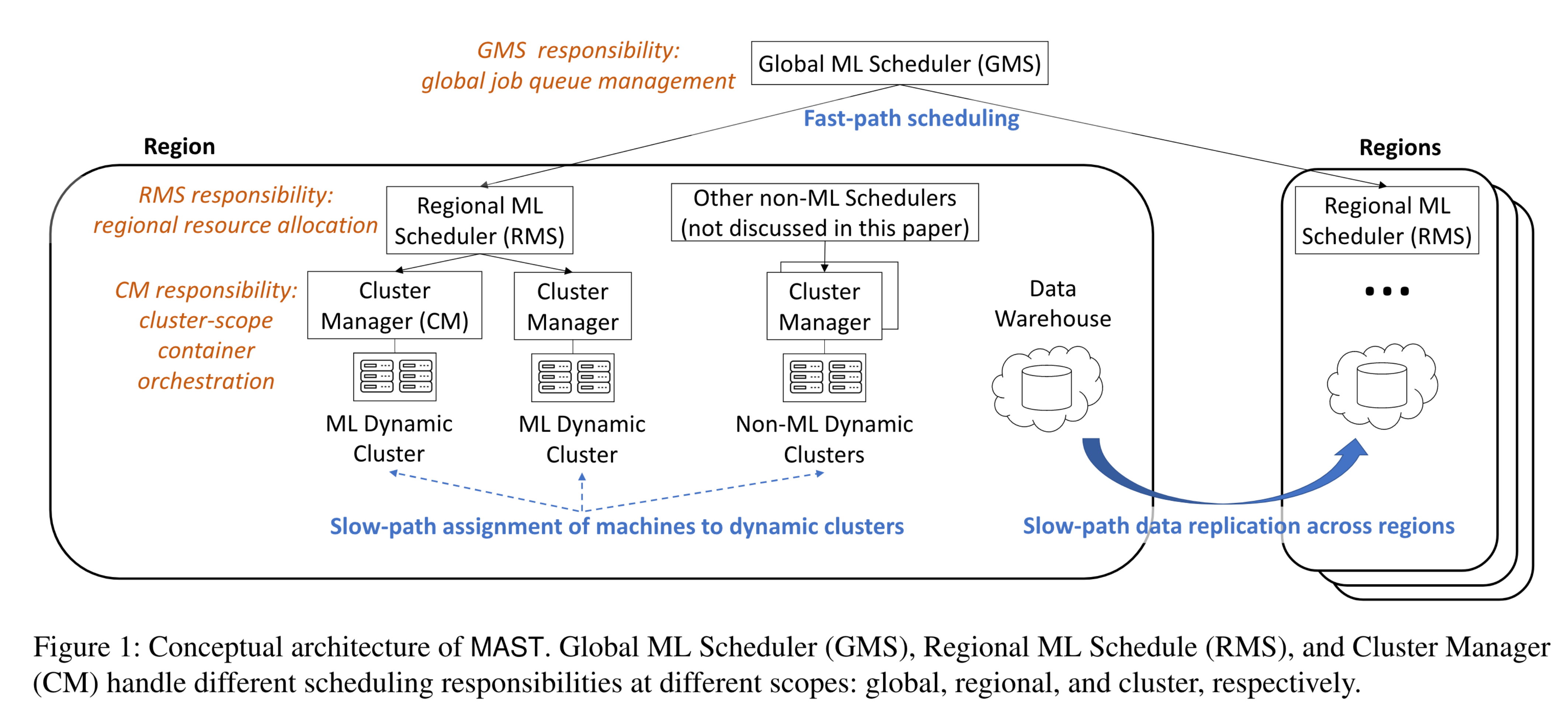
- 为了应对可扩展性挑战,如图 1 所示,MAST 采用三级调度层次结构:全局 ML 调度器 (GMS) 区域 ML 调度器 (RMS) 集群管理器 (CM)。
- 除了管理数据放置之外,慢速路径还通过限制对可用机器的搜索来帮助扩展 RMS。它动态地将机器预先分配给动态集群,允许 RMS 仅搜索 ML 动态集群内的机器并忽略非 ML 动态集群。
- 慢速路径智能地跨区域复制 ML 训练数据,使快速路径能够更轻松地将计算与数据并置。尽管时间安排宽松,但跨区域数据放置仍然非常具有挑战性。
- 2)范围解耦。作业调度系统具有三个主要职责。传统系统在同一范围内(即集群内)处理所有这些职责。
- a)首先,它管理作业队列,当没有足够的资源来运行所有作业时,这需要对作业进行排队和优先级排序。
- b)其次,它处理资源分配,这涉及通过将机器建模为箱子并将任务建模为对象来计算类似装箱的解决方案。
- c)第三,它管理容器编排,执行装箱计划、运行容器并监控其运行状况。
- 我们的主要见解是,所有三个职责共享相同的范围不必要地限制了可扩展性,将作业队列管理和资源分配的潜在更大范围减少到容器编排的最小范围。请注意,容器编排由于其职责繁重,可扩展性最差,因此范围最小。
- 相比之下,如图1所示,我们的范围解耦原则允许三个职责在不同的范围内运行:
- (2.1)作业队列由 GMS 在全局范围内管理,覆盖所有区域的所有待处理作业;
- (2.2)资源分配由 RMS 在区域范围内管理,考虑到区域 ML 动态集群中的所有机器;
- (2.3)容器编排由 CM 在最小的动态集群范围内进行管理。
- 这种方法允许作业队列管理和资源分配在更大的范围内运行,以最大限度地减少搁浅的资源并优化作业安排。一个关键挑战是使 GMS 和 RMS 具有足够的可扩展性,以便在更大的范围内运行。
- 3)穷举搜索。现有系统通常采用联邦方法进行横向扩展。当新作业到达时,联合管理器采用简单的启发式方法将作业分配给负载最少的集群,然后集群管理器管理所有后续操作,包括作业排队、资源分配和容器编排。
- 然而,由于 ML 训练集群几乎总是得到充分利用,因此安排新作业通常需要做出复杂的决策来抢占现有的较低优先级作业。这种复杂性使得简单的联合方法效率较低。
- 我们的主要见解是,与短期分析作业不同,ML 训练作业通常在昂贵的 GPU 上运行很长时间。因此,与其仅搜索一个集群来仓促分配资源,不如对所有相关集群进行详尽的搜索以获得更高质量的布局。如图 1 所示,MAST 的多个 RMS 可以同时计算不同区域中一项作业的资源分配计划,并通过最终拍卖过程确定最佳计划。一个关键障碍是确保 RMS 的可扩展性。
- 1)时间解耦。我们将调度职责分为两条路径:实时作业调度的快速路径和在后台不断优化数据和机器分配的慢速路径。
- 我们做出以下贡献。
- • 1)我们提出全局调度抽象,使用户免受地理分布式数据中心复杂性的影响,并通过跨区域联合放置数据和训练工作负载来提高硬件利用率。
- • 2)我们提出了三个原则——时间解耦、范围解耦和穷举搜索——以可扩展的方式实现高质量的数据和计算布局。
- • 3)我们通过超大规模部署 MAST 展示了全局 ML 调度的有效性,并使用生产数据验证其设计。
📊效果
- MAST 成功平衡了全球区域的负载。在 MAST 之前,对于高优先级工作负载,最过载区域的 GPU 供需比为 2.63。借助 MAST,该比率已降至 0.98,有效消除了过载。
🧠疑问
- 场景规模:数十个Region、数百万机器、数万个GPU。
- 架构:三级调度层次结构
- 感知:不考虑
- 决策:快速负载调度(MIP)、慢速数据调度
- 对本文来说,为了解决数据和工作负载协同带来的影响,提出了“快速负载调度”和“慢速数据调度”两个维度,其中慢速数据调度需考虑数据访问模式,具体来说是什么样的?
- “快速负载调度”使用的是最优化的整数线性规划求解,能够达到什么效率、能够称为“快速”吗?任务需要的响应时间在什么级别?
- 数据和工作负载跨区域是否绝对不可行?什么条件下可行、什么条件下不可行?
- 作业队列、资源分配、容器编排三件事之间的关系是什么?
- 作业队列、资源分配、容器编排的三个范围具体是如何执行的?全局管理同一作业队列是否会导致“作业队列收到用户请求的时延”过长?
- 多个 RMS 间存在“拍卖”形式的协作,具体是如何执行的?
- 希望这篇博客对你有帮助!如果你有任何问题或需要进一步的帮助,请随时提问。
- 如果你喜欢这篇文章,欢迎动动小手给我一个follow或star。
🗺参考文献
- 标题: 【论文】略读笔记78-前沿-Meta跨地域ML训练MAST
- 作者: Fre5h1nd
- 创建于 : 2025-01-10 16:14:28
- 更新于 : 2025-06-24 08:58:49
- 链接: https://freshwlnd.github.io/2025/01/10/literature/literatureNotes78/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。


评论