
【集群】云原生批调度实战:Volcano 深度解析(一):批处理背景需求与Volcano特点

本系列《云原生批调度实战:Volcano 深度解析》计划分为以下几篇,点击查看其它内容。
🖼️ 背景与需求
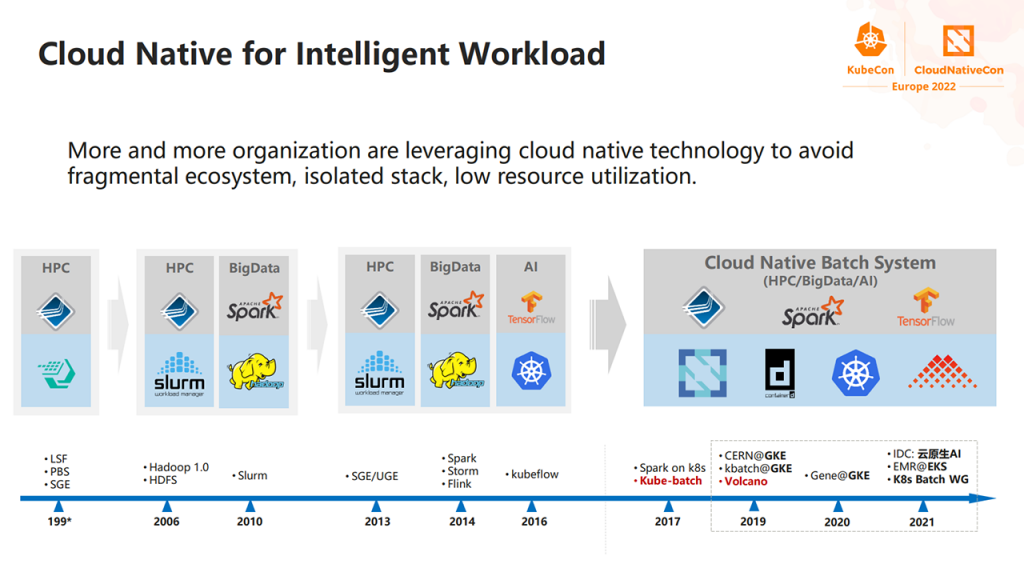
在云原生浪潮下,越来越多的大数据和人工智能框架需要在 Kubernetes(K8s)上运行高性能计算(HPC)应用程序,这对调度系统提出了前所未有的挑战。本文将梳理批处理的发展脉络、核心需求及 Volcano 的定位。
1. 批处理的演进与挑战
发展历程:
- 1990s:以 OpenMPI + Slurm 为代表的 HPC 应用,强调高性能、资源密集型计算。
- 2006 年后:Spark + Hadoop 推动大数据批处理,数据量激增,调度需求复杂化。
- 2016 年后:TensorFlow 等 AI 框架在 K8s 上运行,云原生成为新趋势。
- 多技术生态并存,资源管理和调度愈发复杂,急需统一的批处理调度方案。
关键概念:
- (1)”离线批处理”与”在线实时处理”构成两座大山:[8]
- 批处理:无需人工交互,输入数据预先设定。
- 实时处理:需要用户交互输入。
- (2)”离线批处理”的典型代表为”高性能计算”(HPC)、”大数据”、”AI 工作负载(训练)”。[2,3]
- 批处理(Batch Processing) 是一种计算模式,将任务分组后定时运行,HPC 是批处理的典型应用场景之一。
- HPC 强调利用强大算力处理复杂任务,批处理是其常用的调度和执行方式。
- 组成:HPC 包括高性能的硬件(网络、存储、计算节点)和以批处理为主的软件组织方式。[7]
- (3)HPC 中典型框架:MPI[9]
- MPI(Message Passing Interface):
- 用于多个节点之间高效数据交换,在高性能计算中有广泛应用。
- 是一种抽象的消息传递接口模型,有多种具体实现。
- MPI(Message Passing Interface):
- (1)”离线批处理”与”在线实时处理”构成两座大山:[8]
2. 为什么 K8s 需要批处理调度系统?
Kubernetes 原生调度器主要面向在线服务和微服务场景,对于批处理作业的支持有限,难以满足以下需求:
- A. 作业管理 —— All or Nothing 作业需求支持:
- B. 租户管理 —— 多租户资源共享:
- B1 - 租户感知:没有租户概念、无法用于管理多个租户资源配额、已使用资源等信息。[5]
- 仅有用于认证的Authentication,无法用于资源管理。
- B2 - 租户共享:多个租户共用资源池,需根据供需关系动态分配,低谷互补、高峰公平,避免资源浪费和阻塞。[2,3]
- 由于各租户资源利用情况波动,存在资源利用低谷期和高峰期。低谷期需要互补(闲置资源拿去给有需要的人用)避免浪费、高峰期需要竞争(确保每个人能拿到应得的资源量)保证公平性。
- K8s 仅靠 namespace ,超过配额的请求会被拒绝。这种资源配置方式僵化,难以实现动态公平分配,易造成资源浪费。缺乏作业、租户、命名空间之间的资源共享机制支持(弹性调度、资源借用、资源抢占)。
- B1 - 租户感知:没有租户概念、无法用于管理多个租户资源配额、已使用资源等信息。[5]
- C. 调度功能 —— 高吞吐的多种调度算法:
- D. 工程实践 —— 与计算框架无缝对接:支持主流任务型计算框架。[2,3]
- 对主流计算框架(如MPI、Tensorflow、Mxnet、Pytorch)的支持不足。
- 对每个框架对应不同的operator间协调不足,导致部署和运维复杂。
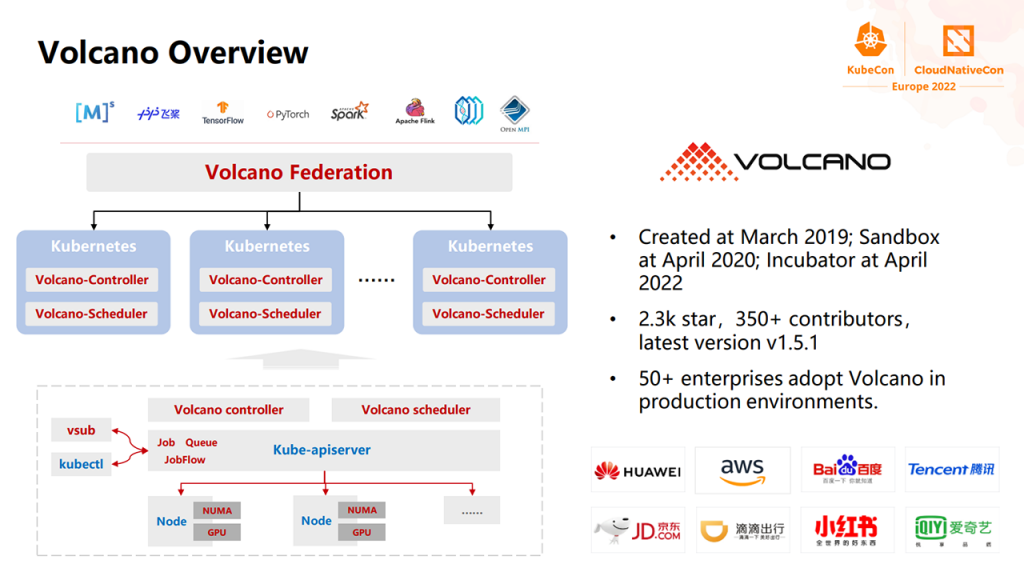
3. Volcano 简介
- 原生K8s调度器:主要针对在线服务设计,采用”先到先得”的调度策略。面向具有资源需求大、运行时间长、依赖关系复杂等特点的批处理作业,原生调度器力不从心,无法满足复杂的调度需求。
- Volcano:基于 K8s 的通用批处理调度系统,专为云原生架构下的 HPC 场景设计。提供了作业管理、队列管理、资源预留等高级特性,特别适合 AI 训练、大数据处理等场景。
项目背景:[2,3]
- 2019 年 3 月创建,6 月由华为云开源并贡献给 CNCF
- 2020 年 4 月成为 CNCF 沙箱项目
- 2022 年 4 月升级为 CNCF 孵化项目
社区活跃度:[2,3,11-13]
- GitHub 星数超过 4.6k
- 有超过 350 位贡献者
- 有稳定的版本更新,2025/02/07已更新至v1.11.0
- 已实现 50+ 落地案例,主要用户包括:腾讯、亚马逊、荷兰ING银行、百度、小红书、滴滴、360、爱奇艺、中科类脑、鹏程实验室、Curise、理想汽车、云知声、喜马拉雅、唯品会、希望组、BOSS直聘等
- 有活跃的 Slack 社区和邮件列表
4. Volcano 核心特性
针对上述需求,Volcano提供了几种典型功能。[1-4]
- A. 作业管理:多种Pod模板,生命周期/错误管理。
- Job、PodGroup等模板:应对作业感知需求。使用 Volcano Job 提供统一作业接口,支持作业内多个任务依赖性感知和管理,支持细粒度的作业生命周期管理。
- Gang调度:应对All or Nothing需求。Job和PodGroup将一组关联的pod当成一个group,从而在pod的概念之上又封装了一层。通过配置minAvailable(最小pod运行数)和replicas(最大pod运行数),实现了对整体group的调度,要么至少minAvailable个pod都成功,要么都失败。
- B. 租户管理:使用队列(Queue)管理多租户资源情况,使用配额(Quota)控制租户可用资源量。
- 队列抽象:应对租户感知需求。通过集群集对象-队列(Queue),与用户user/命名空间namespace解耦,用于配置每个用户应有的资源量/资源比例,从而支持在“多租户”或资源池之间共享资源。
- 队列调度:应对多租户共享-充分利用需求。队列广泛用于共享弹性工作负载和批处理工作负载的资源。特别是,队列可用于
- 在租户或资源池之间共享资源。感知资源需求和资源闲置情况,为突发高需求的作业分配闲置资源。
- 为不同租户或资源池提供不同的调度策略或算法,例如先进先出(FIFO)、公平共享(fair share)、优先级(priority)、SLA。
- 公平调度:应对多租户共享-公平利用需求。批处理工作负载要求在一段时间内公平分配资源,而不是在某个特定时间点。
- 例如,一个用户(或一个特定队列)在某段时间内为运行一个大型作业占用了集群总资源的一半(超过应得的资源量)是可以接受的,但如果这种情况一直持续(可能是作业完成后的几个小时),则该用户(或队列)应受到惩罚,例如使其能够拿到的资源更少。
- C. 调度功能
- Cache组件+调度插件+调度状态优化:应对高吞吐、复杂功能需求。
- Cache组件:缓存集群中的节点和 pod 信息,并根据信息更新作业(PodGroup)和任务(pod)之间的关系,避免反复与 API Server 交互导致的低效。
- 调度插件:支持多种调度策略,如:Gang-Scheduling、Job priority、Job queue、Job order、Preemption、backfill、Job Fair-share、Namespace fair-share、Task-topology、IO-Awareness、Resource reservation、SLA、GPU sharing、NUMA-Awareness、HDRF、Hierarchy Queue、Co-location、Elastic scheduling、TDM、Proportional scheduling。[3]
- 调度状态优化:增加了多个 pod 状态,以便对不同问题分而治之(个人猜测便于多线程流水线处理),提高上述场景中的调度性能。
- 抢占&回收(Preemption & Reclaim):应对多租户共享需求。在低谷期,可以先使用别人的空闲资源;当重回高峰期时,资源所有者将回收reclaim资源。
- Reclaim回收操作用于在队列之间平衡资源,Preemption抢占操作用于在作业之间平衡资源。
- 预留&回填(Reservation & Backfill):应对多租户公平需求。
- 避免大任务饿死starve:当将一个需要大量资源的大规模任务提交给Kubernetes时,如果管道中有很多小任务,则这个大任务可能会因当前调度策略或算法的原因而饥饿或最终被杀死。为了避免饥饿,应该有条件地为任务预留Reservation资源,例如通过设置超时时间。
- 充分利用:进一步地,当资源被预留时,它们可能会闲置或未被使用。为了提高资源利用率,调度器会有条件地将小任务填充Backfill到这些预留的资源中。
- 预留和回填都是根据插件返回的结果触发的。Volcano调度器提供了API,供开发者或用户确定哪些任务被预留或回填。
- Cache组件+调度插件+调度状态优化:应对高吞吐、复杂功能需求。
- D. 工程实践
- Job/PodGroup + K8s计算框架manager组件:对作业抽象,无缝对接计算框架。使用 Volcano Job 提供统一作业接口,适用于 mpi、pytorch、tensorflow、mxnet 等大多数批处理作业,支持多种可扩展的作业插件(Env、Svc、Ssh、Tensorflow)。
🧠疑问
- Volcano的Cache机制理论上可以大大加速调度,但根据Godel测试仍然效率较低,也许这是一个需要重点测试性能的地方。
- Volcano的多种Pod状态机制理论上可以使用多线程加速调度,但不确定实际是否使用了相关功能,也需要重点测试。
- 希望这篇博客对你有帮助!如果你有任何问题或需要进一步的帮助,请随时提问。
- 如果你喜欢这篇文章,欢迎动动小手给我一个follow或star。
🗺参考文献
[1] CNCF - Volcano: Collision between containers and batch computing
[2] Altoros - Volcano: Scheduling 300,000 Kubernetes Pods in Production Daily
[3] KubeCon + CloudNativeCon Europe 2022 - Intro & Deep dive,Volcano: A Cloud Native Batch System
[4] Volcano - Scheduler Actions
[5] 阿里云范佚伦 - YARN/K8s调度Spark作业的对比
- 标题: 【集群】云原生批调度实战:Volcano 深度解析(一):批处理背景需求与Volcano特点
- 作者: Fre5h1nd
- 创建于 : 2025-05-26 11:11:04
- 更新于 : 2025-09-08 10:28:45
- 链接: https://freshwlnd.github.io/2025/05/26/k8s/k8s-volcano-1/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。
推荐阅读
评论