
【集群】云原生批调度实战:Volcano 深度解析(二):Volcano调度流程与调度状态

本系列《云原生批调度实战:Volcano 深度解析》计划分为以下几篇,点击查看其它内容。
💡 简介
前一篇文章总结了 Volcano 作为专为云原生架构下 HPC 场景设计的批处理调度系统,需要解决批处理作业的”作业管理”、”租户管理”、”调度功能”、”工程实践”方面的独特需求。因此,Volcano 在调度方面设计了一系列解决方案。本文将聚焦于 Volcano 的调度流程与调度状态。
🖼️ Volcano 调度流程概览
Volcano 通过一系列组件实现批处理作业的高效调度,主要流程如下:
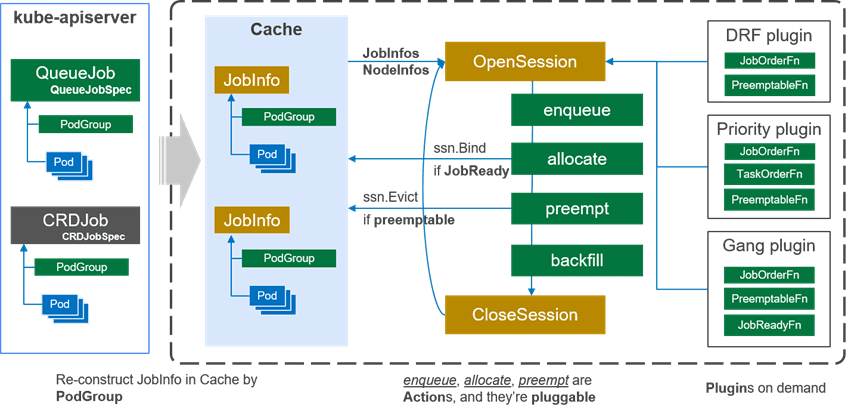
- 缓存(Cache):缓存集群节点和 Pod 信息,维护作业(PodGroup)与任务(Pod)之间的关系。缓存不仅提供集群快照,还为调度程序和 kube-apiserver 之间的交互提供接口(如绑定)。
- 周期性调度:调度器基于集群快照周期性调度作业,每个周期创建会话对象(Session),存储调度所需数据。为了确保分布式系统的信息一致性,Volcano 调度器总是根据某个时间点的集群快照来调度作业,并在每个调度周期内做出一致的决定。
- 调度周期操作——会话开启(OpenSession):每个调度周期依次执行如下核心操作(actions)。此外,在 OpenSession 中,用户可以注册用户定义的插件,如 Gang 和 DRF,为操作提供算法。
- Enqueue(入队):筛选资源满足条件的作业进入待调度队列,确保只有资源充足时才创建 Pod。
- Allocate(分配):为待调度 Pod 分配节点,包含作业排序、节点预选与优选。
- Preempt(抢占):处理高优先级作业对低优先级作业的资源抢占,支持队列内和作业内的抢占。
- Reclaim(回收):跨队列资源回收,高优先级队列可回收低优先级队列的资源,提升整体资源利用率。
- Backfill(回填):为 BestEffort 类型 Pod(无明确资源申请)寻找调度位置,提高资源利用率。
- 插件机制:各 action 可通过插件自定义算法,如 DRF 插件实现作业排序和资源分配。
- 会话关闭(CloseSession):清理调度周期中间数据,准备下一个调度周期。
对于一个调度周期内的各个操作(actions),我们作以下展开叙述:
- Enqueue入队操作:筛选符合要求的作业进入待调度队列。
- 简介:这种机制确保了Pod只会在资源满足的情况下被创建,是调度器配置中必不可少的action。
- 当一个Job下的最小资源申请量不能得到满足时,即使为Job下的Pod执行调度动作,Pod也会因为gang约束没有达到而无法进行调度。
- 只有当集群资源满足作业声明的最小资源需求时,Enqueue action才允许该作业入队,使得PodGroup的状态由Pending状态转换为Inqueue状态。
- 这个状态转换是Pod创建的前提,只有PodGroup进入Inqueue状态后,volcano-controller才会为该PodGroup创建Pod。
- 场景:在AI/MPI/HPC这样的集群资源可能不足的高负荷的场景下,Enqueue action能够防止集群下有大量不能调度的pod,提高了调度器的性能。
- 注意:enqueue action和preempt/reclaim action是互相冲突的,如果同时配置了enqueue action和preempt/reclaim action,且enqueue action判断作业无法入队,有可能导致无法生成Pending状态的Pod,从而无法触发preempt/reclaim action。
- 简介:这种机制确保了Pod只会在资源满足的情况下被创建,是调度器配置中必不可少的action。
- Allocate 分配操作:调度流程中的正常分配步骤,用于处理在待调度Pod列表中具有资源申请量的Pod调度。
- 简介:包括作业的predicate和prioritize。(由于这些操作是通过插件实现的,因此用户可以重新定义自己的分配操作,例如 firmament,一种基于图的调度算法)
- 根据作业顺序(JobOrderFn)对作业进行排序;
- 使用根据节点规则(predicateFn)预选,过滤掉不能分配作业的node;
- 根据节点顺序(NodeOrderFn)对节点进行排序,检查节点上的资源,并为处于作业就绪状态的作业选择最合适的节点。
- 场景:在集群混合业务场景中,Allocate的预选部分能够将特定的业务(AI、大数据、HPC、科学计算)按照所在namespace快速筛选、分类,对特定的业务进行快速、集中的调度。在Tensorflow、MPI等复杂计算场景中,单个作业中会有多个任务,Allocate action会遍历job下的多个task分配优选,为每个task找到最合适的node。
- 注意:Allocate action遵循commit机制,当一个Pod的调度请求得到满足后,最终并不一定会为该Pod执行绑定动作,这一步骤还取决于Pod所在Job的gang约束是否得到满足。只有Pod所在Job的gang约束得到满足,Pod才可以被调度,否则,Pod不能够被调度。
- 简介:包括作业的predicate和prioritize。(由于这些操作是通过插件实现的,因此用户可以重新定义自己的分配操作,例如 firmament,一种基于图的调度算法)
- Preempt抢占操作:调度流程中的抢占步骤,用于处理高优先级调度问题。
- 简介:Preempt用于同一个Queue中job之间的抢占,或同一Job下Task之间的抢占。
- 场景:【官方文档中未解释跨Queue如何发生抢占】
- Queue内job抢占:一个公司中多个部门共用一个集群,每个部门可以映射成一个Queue,不同部门之间的资源不能互相抢占,这种机制能够很好的保证部门资源的隔离性;同一个部门/Queue内部可以枪战。
- Job内task抢占:同一Job下通常可以有多个task,例如复杂的AI应用场景中,tensorflow-job内部需要设置一个ps和多个worker,Preempt action就支持这种场景下多个worker之间的抢占。
- Reclaim回收操作:调度流程中的跨队列资源回收步骤。
- 简介:与Preempt不同,Reclaim专门处理不同Queue之间的资源回收。当某个Queue中的作业需要资源且该Queue未超用时,可以从其他可回收队列中回收资源。
- 场景:
- 跨队列资源回收:在多部门共用集群的场景下,当高优先级部门(如在线业务部门)的Queue资源不足时,可以从其他可回收的部门Queue(如离线计算部门)回收资源。例如,在线业务Queue可以从离线业务Queue回收资源,但离线业务Queue之间不能互相回收资源。
- 资源利用率优化:通过跨队列资源回收机制,集群可以在保证高优先级业务SLA的同时,提高整体资源利用率。当高优先级Queue作业较少时,低优先级Queue队列可以使用闲置资源;当高优先级Queue资源不足时,可以从低优先级Queue回收资源,确保关键业务的资源需求。
- 注意:
- Reclaim在执行时会检查多个条件:目标Queue是否可回收(Reclaimable)、任务是否可被回收(Preemptable)、资源回收后是否满足作业运行需求等,从而确保资源回收的合理性。
- 要使Queue中的作业可以被其他Queue回收资源,需要在Queue的spec中将reclaimable字段设置为true。
- Backfill回填操作:调度流程中处理BestEffort Pod(即没有指定资源申请量的Pod)的调度步骤。【和前面分析的Reservation&Backfill似乎不是一个意思?】
- 简介:与Allocate action类似,Backfill也会遍历所有节点寻找合适的调度位置,主要区别在于它处理的是没有明确资源申请量的Pod。
- 场景:在集群中,除了需要明确资源申请的工作负载外,还存在一些对资源需求不明确的工作负载。这些工作负载通常以BestEffort的方式运行,Backfill action负责为这类 Pod寻找合适的调度位置。
- 插件定义了actions所需的算法。
- 例如,DRF 插件提供了 JobOrderFn 函数,用于根据主导资源对作业进行排序。JobOrderFn 函数根据 DRF 计算每个作业的份额值,份额值越小,说明分配给作业的资源越少,资源将优先分配给该作业。
- DRF 插件还提供了 EventHandler 函数。在作业获得资源分配allocate或抢占资源preempt后,调度程序会指示 DRF 插件更新作业共享值。
🔨 Volcano 调度状态
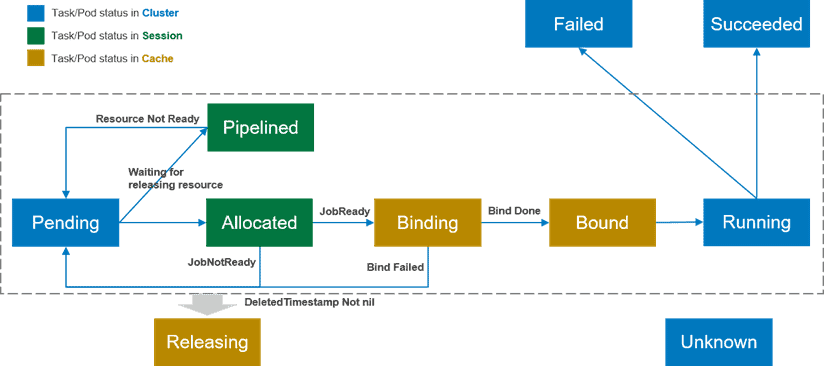
Volcano 增加了多种 Pod 状态以提升调度性能,主要状态如下:
- Pending:Pod 创建后等待调度。
- Allocated:资源已分配但未绑定,调度周期内有效。
- Pipelined:分配到即将释放的资源,调度周期内有效。
- Binding:调度决定已提交,等待 kube-apiserver 确认。
- Bound:kube-apiserver 确认后,Pod 进入 Bound 状态。
- Releasing:Pod 等待删除。
- Running/Failed/Succeeded/Unknown:与 K8s 原生一致。
具体而言:
- Pending 挂起:Pod 创建后,会处于待调度状态,等待调度。其目的是为这些待调度 pod 找到最佳目的地。
- Allocated 已分配:当闲置资源已分配给 pod,但未向 kube-apiserver 发送调度决定时,pod 处于 Allocated 状态。
- Allocated 状态仅在调度周期内存在,用于记录 pod 和资源分配信息。
- 当作业满足启动条件(如 minMember)时,调度程序会向 kube-apiserver 提交调度决定。
- 如果在当前调度周期内无法提交调度决定,pod 状态将回滚到Pending。
- Piplined管道化:此状态与 Allocated 类似。不同之处在于,在此状态下分配给 pod 的资源是其他 pod 正在释放release的资源。
- 此状态在调度周期内使用,不会更新到 kube-apiserver,从而减少了 kube-apiserver 的通信和 QPS。
- Binding 绑定:当作业满足启动条件时,调度程序会向 kube-apiserver 提交调度决定。在 kube-apiserver 返回最终状态之前,pod 仍处于Binding状态。该状态也存储在调度程序的缓存中,并在整个调度周期内有效。
- Bound 绑定:作业调度决定经 kube-apiserver 确认后,pod 将变为Bound状态。
- Releasing 释放:当 pod 等待删除时,它处于释放状态。
- Running运行中、Failed失败、Succeeded成功和Unknown未知:与当前设计相比没有变化。
🏥反思
- 官方文档中未解释跨Queue如何发生抢占,后续还需继续查看代码。
- 官方文档中的Backfill阶段,和上一篇文章分析的Reservation&Backfill似乎不是一个意思,后续还需继续查看具体实践中的操作细节。
- 希望这篇博客对你有帮助!如果你有任何问题或需要进一步的帮助,请随时提问。
- 如果你喜欢这篇文章,欢迎动动小手给我一个follow或star。
🗺参考文献
[1] CNCF - Volcano: Collision between containers and batch computing
[2] Z.S.K.’s Record - Kube-batch学习(批调度器初识一)
[3] Z.S.K.’s Record - Kube-batch学习(queue及podgroup)
[4] Z.S.K.’s Record - Kube-batch学习(核心模块)
[5] Z.S.K.’s Record - volcano如何应对大规模任务系列之volcano关键对象
- 标题: 【集群】云原生批调度实战:Volcano 深度解析(二):Volcano调度流程与调度状态
- 作者: Fre5h1nd
- 创建于 : 2025-05-27 14:36:36
- 更新于 : 2025-09-08 10:28:45
- 链接: https://freshwlnd.github.io/2025/05/27/k8s/k8s-volcano-2/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。
推荐阅读
评论