【集群】YARN 与 Mesos 调度架构深度解析:两级式与单体式的本质区别

💡 前言
在阅读阿里 Fuxi 2.0[1]、字节 Godel[2,3] 等业界先进调度器架构论文时,常会遇到“两级式”调度的概念。初看之下,容易将其理解为“任务调度与资源管理”两级,似乎是将实时问题拆分为长周期(资源管理)和短周期(任务调度)。但深入分析后会发现,这种理解存在矛盾:如 Fuxi2.0、Godel 等主流调度器只负责资源管理,还需要由计算框架的 Application Master 负责任务调度,按上述理解也应该被视为“两级式”,但实际上它们并未被归类为“两级式”。那么,“两级式”到底指什么?YARN 和 Mesos 的本质区别又在哪里?
核心结论
经过认真调研后,得出的结论:单体式、两级式及状态共享式,是面向“资源管理”领域的分类,与“任务管理”无关。
具体案例:
- 两级式调度(以 Mesos 为代表):所有资源管理与调度由两层调度器完成,第一级进行资源粗分筛选,第二级进行资源细分分配。任务管理则由各自的 ApplicationMaster 或 Executor 负责。
- 单体式调度(以 YARN 为代表):所有资源管理与调度均由 YARN 统一完成。任务管理则由 Application Master 负责,包括任务拆分、请求和执行,不涉及资源调度。
详细分析
“两级式”初印象与常见误区
对“两级式”的初印象是“任务调度和资源管理”两级,有一种把实时问题拆分成长周期(资源管理)和短周期(任务调度)两级的错觉。
矛盾所在
但按照以上这种理解,则有一个矛盾无法解释:被分类为“状态共享式”的Fuxi2.0、Godel等主流调度器,本身只负责“资源管理”,还是需要和计算框架中的“ApplicationMaster(负责任务调度)”进行对接;按上述理解,他们也是“两级式”,但实际上却并没有被分类为“两级式”。
根据下文,看起来阿里巴巴论文 Fuxi 2.0[1] 仍然是一个两级式架构:先调度资源(Fuxi 2.0负责)、再在资源上调度任务(其他计算框架的ApplicationMaster负责)。
原文摘录:状态共享架构具有向后兼容性和用户无感性,可以直接和原 Application Master 对接,后者无需进行修改。且后者负责应用级调度。
The shared-state architecture is a neat design that also satisfies our two hard constraints given in §1 (backward compatibility and seamless user transparency). First, interactions between application masters, worker agents and schedulers would require little change. An application master still talks to only one scheduler and performs application-level scheduling on a pool of committed resources. …
共享状态架构是一种巧妙的设计,它还能满足我们在第 1 节中提出的两个硬约束条件(向后兼容性和用户无感性)。首先,应用程序主程序 application masters、工作代理 worker agents 和调度器 schedulers 之间的交互几乎不需要改变。每个 application master 仍然只与一个 scheduler 对话,并在已承诺的资源池上执行应用级调度。…
调研解释
那么两级式架构到底如何理解?
阿里论文原文分析
进一步对阿里 Fuxi 2.0[1] 论文进行具体阅读,找寻线索。原文摘录:
Due to the rapid growth in our businesses in recent years, we have faced serious challenges in scaling our scheduler, which is a centralized architecture similar to YARN [44], as there have been substantially more tasks and machines in our clusters. Today, the size of some of our clusters is close to 100k machines and the average task submission rate is about 40k tasks/sec (and considerably higher in some months). This scale simply exceeds a single scheduler’s capacity and an upgrade to a distributed scheduler architecture is inevitable.
由于近年来我们的业务快速增长,我们在扩展我们的调度程序(与 YARN [44] 类似的集中式架构)时面临严峻挑战,因为我们集群中的任务和机器数量大幅增加。如今,我们一些集群的规模已接近 10 万台机器,平均任务提交率约为每秒 4 万个任务(某些月份甚至更高)。这种规模已经超出了单个调度程序的能力,升级到分布式调度程序架构势在必行。
Our previous cluster scheduler follows a typical master-worker architecture [44]. A single master manages all the resources in a cluster and handles all the scheduling work. Each worker machine has an agent process, which sends the latest status of the worker via heart-beat messages to the master. The master receives jobs submitted by users and then places each job in its corresponding quota group [26](脚注2). The cluster operator configures a quota group to specify the minimum and maximum amounts of resources the group can acquire. In particular, when the cluster is overloaded, resources have to be divided among all the groups by weighted fairness (based on their quotas).
我们之前的集群调度器遵循典型的主从架构[44]。单个主节点管理集群中的所有资源并处理所有调度工作。每个工作节点都有一个代理进程,通过心跳消息将工作节点的最新状态发送给主节点。主节点接收用户提交的任务,然后将每个任务放置在其对应的配额组[26](脚注2)中。集群管理员配置配额组以指定该组可以获取的最小和最大资源量。特别是,当集群过载时,必须通过加权公平(基于其配额)将资源在所有组之间分配。
脚注2:Jobs belong to projects and projects are assigned resource quotas according to their budgets. A quota group can be considered as a virtual cluster.
脚注2:作业属于项目,项目根据其预算分配资源配额。配额组可以被视为一个虚拟集群。
In recent years, the scale of our cluster has significantly increased and a single cluster can have 100k machines. Statically partitioning a large cluster is not an option because there are some extremely large jobs from critical projects and a large cluster is required to ensure that these large jobs and a large number of daily production jobs can be both processed without extended delay. There are also important technical reasons (e.g., resource fragmentation [45], limited visibility [39]) and business factors (e.g., projects need to access the data of other projects in the same business unit that stores its data in a single cluster for operational and management reasons), which require scheduling over an entire large cluster rather than breaking it down into smaller ones.
近年来,我们的集群规模显著扩大,单个集群可拥有 10 万台机器。对大型集群进行静态分区是不可取的,因为有一些来自关键项目的超大型作业,需要一个大型集群来确保这些大型作业和大量日常生产作业都能得到处理,而不会出现长时间的延迟。还有一些重要的技术原因(如资源分散[45]、可视性有限[39])和业务因素(如项目需要访问同一业务部门中其他项目的数据,而该业务部门出于运营和管理原因将其数据存储在单个集群中),都要求在整个大型集群上进行调度,而不是将其分解成更小的集群。
However, the previous monolithic single-master architecture could not handle the scale of the current clusters in Alibaba. First, the 10x larger number of machines requires a larger time gap between two consecutive heart-beat messages from a worker to the master so that the master, which is on the critical path of all decisions, would not be overloaded. But a larger gap is more likely to leave idle machines unused for a longer period of time during the gap. Second, the significantly larger number of tasks simply exceeds the capability of a single scheduler. Specifically, our previous scheduler could only handle task submission rates in the range of a few thousand tasks per second, but the average task submission rate is 40K/sec (and the peak is 61K/sec) for the 30 days in Figure 1a.
然而,以前的单机单主架构无法应对阿里巴巴目前的集群规模。首先,由于机器数量增加了 10 倍,因此需要在工人向主控端连续发送两条心跳消息之间留出更大的时间间隔,这样处于所有决策关键路径上的主控端才不会超负荷。但更大的时间间隔更有可能使闲置机器在间隔期间有更长的闲置时间。其次,大量的任务根本无法满足单个调度程序的需求。具体来说,我们之前的调度程序只能处理每秒几千个任务的提交率,但图 1a 中 30 天的平均任务提交率为 40K/秒(峰值为 61K/秒)。
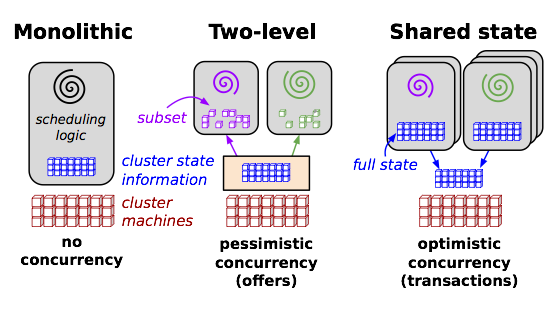
Omega [39] proposed the shared-state scheduler architecture as described in §1. This architecture addresses the limitations in monolithic, two-level, and static partitioning approaches, respectively. First, each scheduler in the shared-state architecture can run a different scheduling strategy programmed in separate code bases for different types of jobs, as to avoid the software engineering difficulties of maintaining all strategies in one code base and using multi-threading for solving head-of-line blocking in monolithic architecture. Second, each scheduler has a global view of the cluster, thus solving the problem of limited visibility in two-level schedulers such as Mesos [25]. This allows global policies (e.g., fairness and priority) to be implemented. Third, each scheduler can assign tasks to any machine in the cluster instead of a fixed subset of partitions, which reduces resource fragmentation in statically partitioned clusters and achieves higher utilization [45].
Omega [39]提出了第 1 节所述的共享状态调度器架构。该架构分别解决了单片、双层和静态分区方法的局限性。首先,共享状态架构中的每个调度器可针对不同类型的作业运行不同的调度策略,这些策略在不同的代码库中编程,从而避免了在单片架构中将所有策略维护在一个代码库中以及使用多线程解决行头阻塞的软件工程难题。其次,每个调度器都有集群的全局视图,从而解决了 Mesos [25] 等两级调度器的有限可见性问题。这使得全局策略(如公平性和优先级)得以实施。第三,每个调度器可以将任务分配给集群中的任何一台机器,而不是固定的分区子集,这就减少了静态分区集群中的资源碎片化,实现了更高的利用率[45]。
上述内容中,可以得到两个结论:
- 提到的单体式代表为 YARN(这与 Google 的 Omega 调度器论文中一致。而在字节 Godel 调度器论文中将 YARN 视为两级式,个人认为这是有误的)。
- 提到的两级式调度器代表为 Mesos。
代表性架构细化调研
对于上述两个结论,进一步通过调研相关资料,分析 Mesos (两级式代表)和 YARN (单体式代表,但也有论文将其视为两级式)的具体调度流程:
Mesos介绍
- 总体出发点:根据相关博客[4],Mesos想取代的是静态分区集群。其“两级式”是仅在资源层面调度的“两级”(Mesos Master + Framework Scheduler,后者由各框架额外实现),任务层面调度(如任务分解、多任务间数据传输等)还是依靠各框架原本的任务调度器(Application Master 及 Executor)。
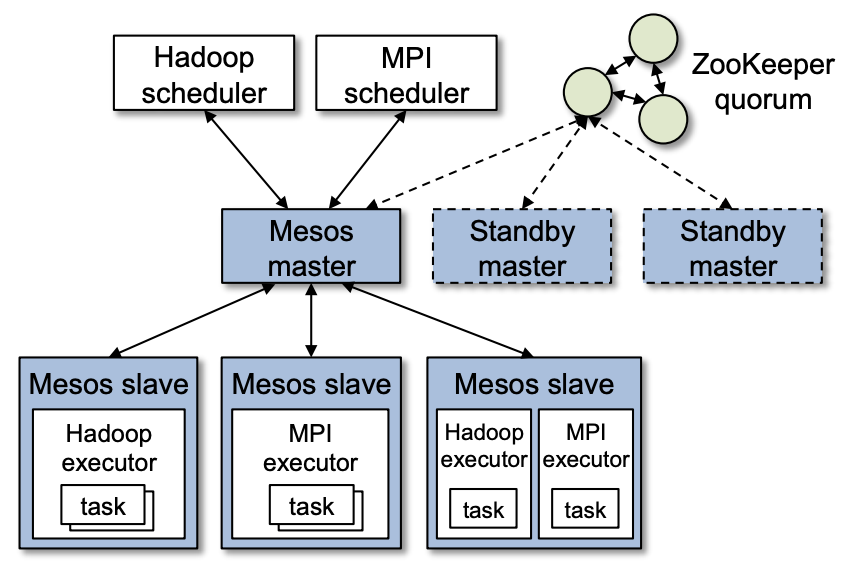
- 整体流程:具体来说,如上图2所示,Mesos Master(第一级调度)会筛选出一部分资源给 Framework Scheduler 框架调度器(HadoopScheduler、MPIScheduler,第二级调度器),框架的调度器进行从中选择具体资源调度。
- 具体流程:根据具体解析文章[5,6,7]第二、四篇文章,更具体的流程如下图3。
- 各 Node(Mesos Slave) 上报,有一块“空闲资源”;同时 Application Framework 有一堆作业排队等待(来自各框架 Application Master)。
- Mesos Master 第一级调度:根据自定义目标(论文中实现了两种默认插件,一个使用max-min fairness公平性为目标,一个使用预设的绝对优先级strict priorities为目标)筛选作业(此外需要补充一点,和目前主流K8s调度架构不太一样,这一级是资源找作业、而非作业找资源),按优先级向筛选出的 Framework 发起邀约。
- Framework Scheduler 第二级调度:根据邀约信息,决定是否接收资源邀约、以及要将哪个作业调度到哪个服务器上。

YARN介绍
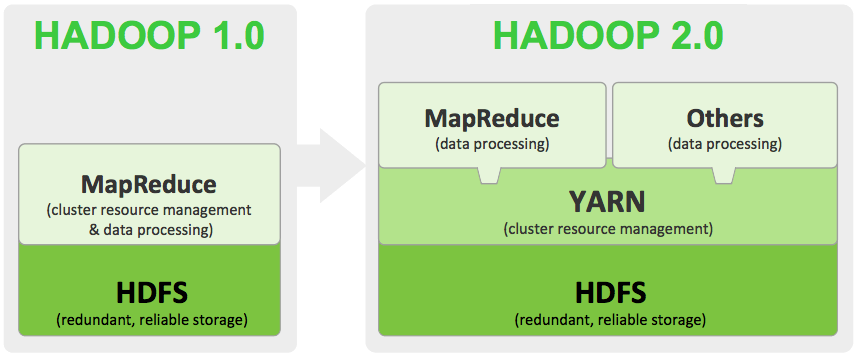
- 背景:根据相关博客[8,9],如上图4所示,YARN (Yet Another Resource Negotiator) 是 Hadoop1.0 到 2.0 升级后的产物,是 Hadoop1.0 中的资源管理模块被独立出来的结果。在 Hadoop2.0 中除了 YARN 还有专门的 Application Master。
- 总体出发点:如背景所述,将资源调度和任务调度拆分为两个模块 YARN 和 Application Master。Application Master 只是 YARN 的一个 Application,可以理解为一个业务进程(参考知乎回答[10]的评论区),不参与调度、只参与任务发起和执行。
- 具体流程:只有 Yarn Resource Manager 一个组件在调度,Application Master 不参与调度、只参与拆分需求和执行任务,更具体的流程如下图5。
- Application Client 发起请求(多阶段工作流);同时 Node Manager 持续通过心跳状态进行上报。
- YARN Resource Manager 收到请求后直接调度,在第一个调度决策位置创建容器,并启动 Application Master。
- Application Master 在容器中拆分作业为任务请求,变成新的请求发起方(如第1步),发起请求。
- YARN Resource Manager 收到请求后继续调度,将调度决策告知 Application Master,Application Master 在对应位置运行后续任务。

总结与趣闻
结论
两级式中,两层调度器都是进行资源管理,第一层粗分、第二层细分。
如果把任务管理也算进来,其实可以视为三级式。
具体来说:
- Mesos 是两级式架构。所有资源管理与调度由两层调度器完成。第一级是粗筛,将一批符合要求的资源提供给各框架做选择;第二级是具体调度,决定要用哪些资源执行作业。后续还会有任务管理器(Application Master 或 Executor)负责拆分任务、执行任务。
- YARN 是单体式架构。所有资源管理与调度均由 YARN 统一完成。任务管理则由 Application Master 负责,包括任务拆分、请求和执行(类似 Mesos 中的 Executor),这部分不涉及资源调度。
另一个角度[8]:Mesos 和 Yarn 资源分配粒度不同。
- Mesos Master 只负责为计算框架粗粒度筛选一批资源,具体的细粒度资源分配计算框架侧(Framework Scheduler)实现。这两者共同组成了“两级式”调度。
- Yarn 则直接全权负责细粒度资源分配。
趣闻1
补充一点有意思的故事1[11]:
- Borg(google) 很早就在谷歌内部使用,但在 2015 年才公布。其中混部和超卖的思想到十几年后的现在才被业界系统开始探索。
- Mesos(Twitter) 2012 年发布,当年红极一时,后来被 K8s 替代。
- YARN(Apache) 2013 年发布。
趣闻2
补充另一个有意思的故事2[10,12]:Spark 早期是为了推广 Mesos 而产生的,这也是它名字的由来,不过后来反而是 Spark 火起来了……
- 2009 年,Apache Spark(以下简称 Spark)诞生于加州大学伯克利分校(University of California, Berkeley)AMP 实验室,2013 年被捐献给 Apache 基金会。
- 实际上,Spark 的创始团队本来是为了开发集群管理框架 Apache Mesos(以下简称Mesos)。Mesos 开发完成后,需要一个基于 Mesos 的产品运行在上面以验证 Mesos 的各种功能,于是他们接着开发了 Spark。Spark有火花、鼓舞之意,创始团队希望用 Spark 来证明在 Mesos 上从零开始创造一个项目非常简单。
- 如今,Spark 已经成为大数据分析领域绝对的王者,而 Mesos 反而没有那么有名,真可谓无心插柳柳成荫。
趣闻3
关于 YARN 起名的一些引申[10]:
- YARN 的全称是 “Yet Another Resource Negotiator”,意思是“另一种资源调度器”,这种命名和“有间客栈”这种可谓是异曲同工之妙。
- 以前 Java 有一个项目编译工具,叫做 Ant,他的命名也是类似的,叫做 “Another Neat Tool”的缩写,翻译过来是”另一种整理工具“。
结语
通过对 YARN 与 Mesos 两种主流调度架构的深入剖析,可以看出,两级式与单体式的本质区别在于资源调度权力的分层与集中。理解这些架构的设计思想与演进脉络,有助于我们更好地把握大规模集群调度系统的未来发展方向。
- 希望这篇博客对你有帮助!如果你有任何问题或需要进一步的帮助,请随时提问。
- 如果你喜欢这篇文章,欢迎动动小手给我一个follow或star。
🗺参考文献
[2] Github - Gödel Unified Scheduling System
[4] 集群管理系统 Mesos 的设计原理 · NSDI ‘11
[5] 深入浅出Mesos(二):Mesos的体系结构和工作流
- 标题: 【集群】YARN 与 Mesos 调度架构深度解析:两级式与单体式的本质区别
- 作者: Fre5h1nd
- 创建于 : 2025-06-04 19:51:52
- 更新于 : 2025-06-11 16:46:13
- 链接: https://freshwlnd.github.io/2025/06/04/k8s/scheduler-yarn-vs-mesos/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。