
【论文】精读笔记7-前沿-Meta跨地域ML训练MAST-B-相关工作发展脉络梳理

📖《MAST: Global Scheduling of ML Training across Geo-Distributed Datacenters at Hyperscale》
2024 年 Meta、The Ohio State University团队 发表于 CCF-A 类会议 OSDI。
系列博客:
Meta 公司 机器学习训练背景 Background of ML Training at Meta
数据中心和硬件 Datacenter and hardware
我们的私有云由数十个区域和数百万台机器组成。
- 一个区域包括多个相互靠近的数据中心。
- 跨区域网络带宽比区域内数据中心之间的分段带宽低约 10 倍。
- 数据中心的部分区域被 ML 训练集群占据,这些集群的机器配置了多个 GPU,并通过 8x200Gbps RoCE 网络和 4x100Gbps 以太网连接。
ML 训练是数据密集型的,因此更倾向于将训练工作负载的计算和数据放在同一地点。
- 对于属于同一 ML 训练工作负载的任务,我们倾向于将它们依次放置在同一个机架、集群、数据中心和区域中。
- 将计算和数据分开放置在不同区域或将任务放置在不同区域会导致无法接受的性能。
一直以来,数据中心硬件都是根据不同时期的具体需求逐步采购的,这导致了硬件类型在不同地区的分布不均。Flux 对此进行了讨论,图 2 也显示了这一点。
- 这种不均衡使得数据和计算难以同地放置,需要进行全局优化。(根据资源情况,选择数据和计算分布;必要时复制后分别拆开放,而非一股脑堆在一起)
- 例如,
- 由于 Region6 缺少 GPU,因此最好将基于 CPU 的分析作业使用的数据放在 Region6。
- 如果一些基于 GPU 的 ML 训练工作负载与这些分析作业共享相同的数据,我们也应该将它们安排在 Region6 中。
- 但是,如果此类 ML 工作负载过多,我们就必须将它们的数据复制到其他区域并在那里执行。

动态集群 Dynamic clusters
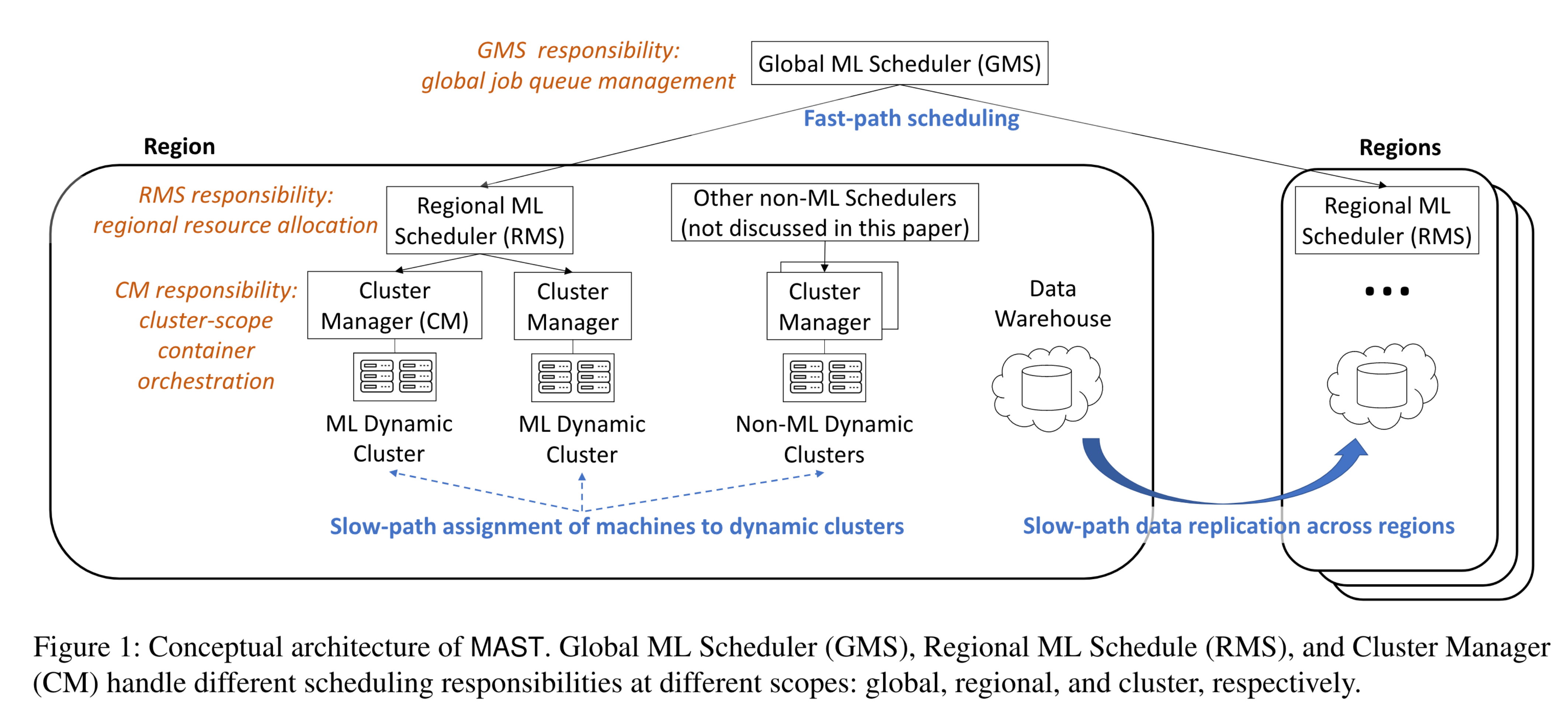
如图 1 所示,一个名为 RAS 的慢速路径组件将机器预先分配到动态集群,这在 RAS 论文中被称为 “保留 Reservations”。
- MAST方案:这样,区域 ML 调度器(RMS)就可以只搜索 ML 动态集群内的机器,从而实现扩展。
- MAST 消耗 RAS 的输出(即 RAS 创建的动态群集),MAST 的调度决策不会影响或反馈到 RAS。
- RAS方案:通常,一个 ML 动态集群包括 GPU 和 CPU 机器。为了更新动态群集,RAS 将一个区域内的所有机器作为输入,并对每个动态群集的预定规模和对某些硬件类型的偏好进行新的或更新的规范。
- RAS 提出了一个 MIP 问题,用于为动态集群分配机器。
我们将简要介绍 RAS,详情请读者参阅 RAS 论文[2]。
- 背景:RAS 可确保分配给动态群集的机器总容量满足管理员指定的要求,并包含足够的缓冲区来处理随机和相关机器故障。相关故障(如数据中心内大型故障域的断电)可能导致数以万计的机器无法使用。
- 方案:
- RAS 将动态集群的机器分布在不同的故障域中,以确保在大型故障域发生故障时,仍有足够的健康机器可用。
- 此外,RAS 还能确保每个数据中心的计算机器与存储机器比例适当,从而减少不必要的跨数据中心通信。
- 最后,RAS 会定期(如每 30 分钟)重新运行优化,以适应变化。
- 例如,当新的数据中心上线时,RAS 可以将动态群集的机器进一步分散到这些新的数据中心,从而减少处理相关故障所需的缓冲区大小。
机器学习训练负载 ML training workload
一个训练工作负载 workload包含多个异构作业 jobs,每个作业 job 包含多个同构的任务 tasks,而任务 task 被映射到一个Linux容器 container中。因此,层次结构是工作负载→作业→任务。
- 例如,一个训练工作负载可能包括(1)执行反向传播训练的训练作业;(2)数据预处理作业;(3)参数服务器作业;以及(4)评估作业,用于评估生成的模型。
工作负载的所有任务需要集体调度Gang Scheduling,即它们必须一起分配。
- 理论上,如果一个训练作业使用的GPU少于一个完整的GPU,可以使用多实例GPU(MIG)或其他软件方法将GPU共享给多个作业。
- 然而,在实践中,由于训练数据量庞大,我们所有的训练作业至少使用一个完整的GPU。
数据仓库 Data warehouse
我们的数据仓库在三级层次结构中存储了数十亿字节的数据:数百个命名空间→数百万个表→数十亿个数据分区。
- 分区一旦创建就不可更改,但可以在现有表中添加新的分区。
- 例如,”user_activity “表每天都可以添加一个新分区,以记录过去 24 小时内的用户活动。
有些数据分区同时用于 ML 训练和数据分析,如 Spark 和 Presto。我们开发了一个名为 “俄罗斯方块”(Tetris)的系统,它能在考虑到 Spark、Presto 和 ML 训练作业的数据访问模式的情况下,优化跨区域的数据放置。
负载共享数据分区 Sharing of data partitions by workload

图 3 显示,数据分区经常被多个 ML 工作负载共享。
- 在 P50、P90 和 P99 百分位数下,一个数据分区分别被 3、17 和 45 个不同的工作负载共享。
- 数据共享使数据放置问题变得复杂,因为跨区域迁移一个数据分区可能需要迁移依赖于该分区的多个工作负载。
- 此外,为了防止负载失衡,有必要在多个区域复制最热门的分区,否则大量依赖于这些分区的工作负载将被迫在少数区域运行。
机器学习训练作业的长执行时间 Long execution time of ML training jobs
ML 训练是资源密集型工作,可能需要很长时间才能完成。
- 在 Meta,ML 训练工作负载的完成时间往往是 Spark 分析作业的 10 倍。因此,次优放置决策会对 ML 训练产生更大的负面影响。这就是本文所述的穷举搜索原则的动机。
- 此外,当工作负载在更多机器上、运行更长时间时,工作负载调度吞吐量也会下降。
- 因此,如图 1 所示,分别在全局和区域范围内管理作业队列和资源分配是可行的,而不是在导致更多碎片的小集群级别进行管理。
配额逾期作业抢占 Quota and job preemption
不同优先级的训练工作负载按优先级分配容量配额。
- 如果一个团队的容量使用在配额内,MAST 保证在一定的延迟内启动其培训工作负载。
- 一旦团队超出配额,他们仍可提交工作负载,以最低优先级伺机运行,但当更高优先级的工作负载到来时,他们将被抢占。
- 因此,出于实验目的的低优先级工作负载总是能充分利用培训集群。
- 调度新的工作负载往往涉及抢占低优先级作业的复杂决策。这种复杂性使简单的联邦管理器Federation Manager变得不那么有效。
用于恢复的检查点 Checkpoint for recovery
训练工作负载会定期检查其状态。
- 当一台机器出现故障时,集群管理器会在替代机器上重启工作负载,使其能够从检查点恢复状态并继续执行。
- 在为高优先级工作负载抢占低优先级工作负载之前,集群管理器还会保存一个检查点,以便日后恢复。
- 随着我们不断缩短保存检查点所需的时间,我们正逐步增加检查点的频率,以尽量减少恢复过程中两个检查点之间丢失的工作量。
- 随着大型语言模型的训练工作量不断增加,恢复成本也越来越高,这一点变得越来越重要。
对于机器学习/非机器学习负载,使用分离的应用级调度器 Separate application-level schedulers for ML and non-ML workloads
如图 1 所示,ML 和非ML 工作负载由不同的调度器管理。
- Twine 的可扩展架构允许所有工作负载共享一个用于机器和容器管理的通用集群管理器,同时针对特定工作负载采用不同的应用级调度器。例如,
- MAST 用于 ML 训练工作负载,
- Shard Manager 用于有状态数据库,
- Turbine 用于流处理,
- Chronos 用于分析作业。
- 每个应用级调度程序都针对特定目的进行了优化。例如,
- Shard Manager 针对数据库的高可用性进行了优化,
- Chronos 针对短期分析作业的高调度吞吐量进行了优化,
- 而 MAST 则针对高质量决策和数据-GPU 主机托管进行了优化。
🧠疑问
- 本文可作为“跨地域供需不均衡”的论据,且强调了“不同区域资源供应有差异”是历史原因、由于设备都是逐批采购的。
- RAS和我们之前考虑过的“动态分区”很像,在Godel中提过这种方案原本在字节服务器中也有使用、但是调整频率还不够高所以有滞后性。
- META对任务层级的命名和业界主流不同,不知道是出于什么考虑。不过本质都是一样的三层架构。
- META:工作负载→作业→任务
- 业界主流:作业→任务→实例
- Gang Scheduling要求的是“作业中的实例”(或用本文说法就是“工作负载中的任务”),在Volcano的yaml文件中也可以看出。
- 在META,每个训练作业至少使用一个GPU(因为训练数据量大)。这是一个比较强的假设,可能是为了方便后续形式化定义和算法说明。但想来是有优化空间的。
- 数据分区(数据集)放置和复制的权衡会是一个需要解决的问题。
- 在META,ML 训练工作负载的完成时间往往是 Spark 分析作业的 10 倍,是一个可以使用的论据。
- 如果仅在一个小集群内调度,可能会产生更多的碎片,从而导致调度吞吐量下降。
- 当存在抢占决策时,多调度器运行会变得更困难。
- 在META中,Twine架构下可同时使用Shard Manager、Turbine、Chronos等管理器,但多种架构同时运行会对MAST调度带来什么影响没有明确?
- 希望这篇博客对你有帮助!如果你有任何问题或需要进一步的帮助,请随时提问。
- 如果你喜欢这篇文章,欢迎动动小手给我一个follow或star。
🗺参考文献
- 标题: 【论文】精读笔记7-前沿-Meta跨地域ML训练MAST-B-相关工作发展脉络梳理
- 作者: Fre5h1nd
- 创建于 : 2025-06-24 08:05:59
- 更新于 : 2025-06-26 10:33:36
- 链接: https://freshwlnd.github.io/2025/06/24/literature/literatureNotesIntensive7/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。


评论