【论文】略读笔记86-前沿-DLRM的CPU-GPU分解调度

📖《GPU-Disaggregated Serving for Deep Learning Recommendation Models at Scale》
2025 年 香港科技大学+阿里巴巴团队 发表于 CCF-A 类会议 NSDI。
作者之一刘侃提到:实际工作在 n 年前就完成了,论文写作在 n-m 年前就完成了~[2,3]连这样的论文都花了这么久[/惊恐]
RTP(Real Time Prediction)[4]平台是阿里内部一个通用的在线预测平台,广泛支持淘天、本地生活、AIDC、菜鸟、大文娱等搜索和推荐业务场景的 DLRM(Deep Learning Recommendation Model)部署。自2022年起,RTP开始探索大规模GPU-Disaggregation技术的落地,运用RDMA高性能网络通信构建GPU-CPU全分离的分布式推理系统。
🎯需求
- 在线推荐系统使用深度学习推荐模型(DLRMs)提供准确、个性化的推荐以提升用户体验。
- 个性化推荐系统是许多面向用户、创造收入的网络服务的关键基础设施,如内容流媒体、电子商务、社交网络和网页搜索。这些系统使用深度学习推荐模型(DLRM)提供准确、个性化的推荐,以改善客户体验并增加用户参与度。
- 根据Meta的数据,DLRM服务消耗了当今AI云中大部分的推理资源,顶级推荐模型占用了超过79%的AI周期。
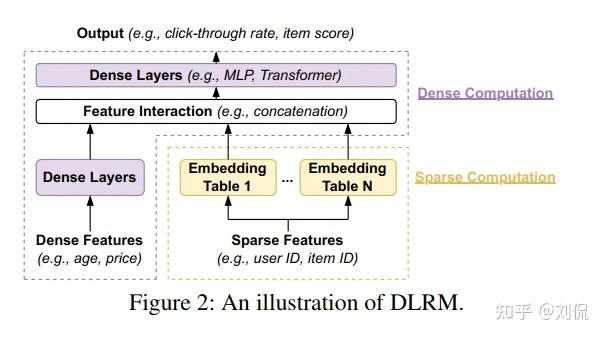
DLRM特点
鉴于现在 LLM 很火,作者之一刘侃用下面的表格对比了两者在线部署角度的差异,以便更好地理解问题。
如果想了解更多 DLRM 的信息,可以参考原文或相关博客[2,3],或原博客推荐的“典中典 W&D[5]以及系统介绍[6]”。
模型特点对比:
|-| DLRM | LLM |
|—|—|—|
|Feature Engineering| ID 化、统计、笛卡尔积、查外表…太多了| Tokenize,字符到 int 的 ID 转换|
|Feature Store| 100G-10T 量级,有行为序列、商品属性等| 额,如果是说 tokenizer 表的话,那就是 M 级别。|
|Embedding| 10G-1T 量级,大规模稀疏| <10G|
|Model| DNN + Attention 等变种结合| Transformer/Mamba,没了|
对应算力特点对比:
| - | DLRM | LLM |
|---|---|---|
| CPU | 负载重,大量特征查表(如 KV)和计算。不同模型之间负载差距大,有 32c:1GPU 也有 128c:1GPU。 | Tokenize 开销很小,剩下还有少量 Framework 和 KernelLaunch 开销。8c 算多的。 |
| GPU | 模型杂,方法多,实验也多;模型输入偏小,Kernel Launch 开销较大,算力利用有限。 | 社区很卷,都是标准算子,接近硬件算力极限。 |
🚧现状
- 然而,大规模高效提供DLRM服务具有挑战性。
- DLRMs表现出独特的资源使用模式:它们需要大量的CPU核心和巨大的内存,但只有少量GPU。
- DLRM提供具有严格的延迟服务级别目标(SLO),通常每个请求在数十毫秒的规模。同时,DLRM提供需要处理需求的频繁波动。满足延迟SLO通常意味着为峰值负载提供资源,这可以显著高于平均水平。
- 在多GPU服务器上运行它们会迅速耗尽服务器的CPU和内存资源,导致大量未分配的GPU闲置,无法被其他任务利用。
- 图1说明了阿里巴巴DLRM服务在生产集群中的资源需求。我们观察到明显的日间模式,峰值与谷值之比超过6倍;在季节性促销活动中,峰值负载可以比常规峰值高1.3倍,这与之前的报告一致。在如此规模上为峰值负载提供资源会导致显著的低利用率,使其在经济上不可行。
- 为了减少过度配置,更好的策略是为平均负载进行配置,并在负载高峰期间启用容量借贷。
- 像阿里巴巴这样的大型公司拥有多个特定用途的基础设施:一些用于训练,其他用于推理。当DLRM服务处于高峰时段时,它可以暂时从训练集群借用GPU服务器,因为训练作业对延迟不敏感,可以容忍中断。
- 然而,服务器池操作之间存在不匹配。
- 与需要大量GPU周期的训练任务不同,推荐模型表现出较低的计算强度,并且不依赖于GPU。相反,它们执行稀疏计算,如嵌入,这需要大量内存来存储嵌入表,以及许多CPU核心用于查找和池化操作。因此,在训练服务器上运行推荐模型会迅速耗尽服务器的CPU和内存资源,留下大量未分配的GPU闲置。
- 在我们的集群中,典型的DLRM服务请求48个CPU和1个GPU,而训练服务器通常有〈96个CPU,8个GPU〉。部署两个DLRM推理实例将占用主机上的所有CPU,留下6个未分配的GPU无法被其他任务利用。

🛩创新
- 本文描述了Prism,一个生产级DLRM服务系统,通过资源解耦的方式消除GPU碎片化。
- Prism运行在共享基础设施上,其中一组CPU节点(CNs)通过高速RDMA网络与一组异构GPU节点(HNs)互连,形成两个可以独立扩展的资源池。
- 每个CN拥有大量CPU核心和高内存,但没有GPU,而每个HN是一个典型的具有多个GPU但CPU和内存资源有限的训练服务器。
- 这种基础设施将具有固定配置的单体服务器集群分解为两个解耦的资源池,其中CNs提供丰富的CPU和内存资源,而HNs提供大量的GPU。这两个资源池可以独立扩展以匹配动态工作负载的变化需求。
- Prism自动将DLRMs划分为CPU密集型和GPU密集型子图,并在CNs和HNs上调度它们以实现解耦服务。
- 给定一个DLRM,Prism自动将其计算图分为两个子图,一个包含CPU和内存密集型操作符,另一个GPU密集型。然后,系统将这两个子图调度到选定的CN和HN上进行解耦服务,并将结果返回给用户。
- Prism运行在共享基础设施上,其中一组CPU节点(CNs)通过高速RDMA网络与一组异构GPU节点(HNs)互连,形成两个可以独立扩展的资源池。
- 本文还描述了在生产规模下构建解耦的DLRM系统所面临的挑战、技术和经验教训。Prism采用各种技术来最小化由解耦引起的延迟开销,包括最优图划分、拓扑感知资源管理和SLO感知通信调度。
- 首先,解耦需要对模型所有者透明。
- 手动重构模型到解耦版本会增加精度下降的风险,并需要模型所有者额外的努力,因此是不理想的。
- 其次,系统应扩展到数千台服务器以处理过度的负载峰值。
- 鉴于流量激增,它应迅速将工作负载调度到大量服务器上,以在短时间内实现显著的总吞吐量。
- 第三,系统应满足DLRM服务的严格延迟SLO,由于GPU解耦导致CN和HN之间存在非平凡的通信开销。
- 首先,解耦需要对模型所有者透明。
- Prism通过三个主要组件应对这些挑战:
- 一个解耦优化的实时预测(RTP)框架,该框架在CN和HN之间最优地划分计算图(第4.1节),
- 一个拓扑感知的资源管理器,该管理器最小化服务器间和服务器内的通信开销(第4.2节),
- 以及SLO感知的通信调度,确保在目标延迟SLO内进行解耦服务(第4.3节)。
- 总结而言,我们的主要贡献如下:
- • 我们在部署生产规模的弹性DLRM服务时,识别了资源配置的挑战,并激励了GPU解耦服务的需求。
- • 我们设计和实现了Prism,通过解耦服务从CPU节点和异构GPU节点中收集资源,缓解了服务器配置与DLRM资源需求之间的不匹配,同时仍满足延迟SLOs。
- • 我们在生产环境中评估了Prism,并证明它可以有效地减少资源碎片化,而不会损害服务性能,在促销活动期间实现高效的容量借贷。
- 我们将生产DLRM服务跟踪作为阿里巴巴集群跟踪计划的一部分发布[7]。
📊效果
- 评估表明,Prism在拥挤的GPU集群中有效地将CPU和GPU碎片化降低了53%和27%。在季节性促销活动中,它有效地实现了从训练集群的容量借贷,节省了超过90%的GPU(§5)。Prism已在生产集群中部署超过两年,现在运行在超过10k个GPU上。
⛳️未来机会
- 操作经验。生产集群经常采用在线和离线任务的混合部署以提高效率。但在我们的情况下,分类的DLRM服务引入了频繁的RDMA网络通信。
- 我们观察到,即使获得RNIC,RDMA转移潜伏期也可以在强烈的资源争夺中增加十倍。根本原因是在容器覆盖网络下,RDMA和TCP都依赖于覆盖网络方案进行通信。混合工作负载的TCP流量会影响网卡底层的流表逻辑,从而影响RDMA流量。
- 我们当前的解决方法涉及监视节点资源利用率和在线服务延迟,并在指标变得异常时触发离线任务的驱逐。我们认为这是未来研究的一个开放问题。
- 希望这篇博客对你有帮助!如果你有任何问题或需要进一步的帮助,请随时提问。
- 如果你喜欢这篇文章,欢迎动动小手给我一个follow或star。
🗺参考文献
[2] GPU,CPU,谁是谁的“伴侣”?—— 阿里 RTP 平台的异构资源解耦大冒险 - InfoQ
[3] 解读 NSDI25 GPU-Disaggregated Serving for Deep Learning Recommendation Models at Scal - 知乎
- 标题: 【论文】略读笔记86-前沿-DLRM的CPU-GPU分解调度
- 作者: Fre5h1nd
- 创建于 : 2025-08-13 12:10:32
- 更新于 : 2025-08-13 12:10:35
- 链接: https://freshwlnd.github.io/2025/08/13/literature/literatureNotes86/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。


