
【集群】云原生批调度实战:Volcano性能瓶颈猜想验证与实验总结

本系列《云原生批调度实战:Volcano 监控与性能测试》计划分为以下几篇,点击查看其它内容。
- 云原生批调度实战:调度器测试与监控工具 kube-scheduling-perf
- 云原生批调度实战:调度器测试与监控工具 kube-scheduling-perf 实操注意事项说明
- 云原生批调度实战:调度器测试监控结果
- 云原生批调度实战:本地环境测试结果与视频对比分析
- 监控与测试环境解析:测试流程拆解篇
- 监控与测试环境解析:指标采集与可视化篇
- 监控与测试环境解析:Go 项目解析与并发编程实践
- 监控与测试环境解析:自定义镜像性能回归测试
- 监控与测试环境解析:数据收集方法深度解析与Prometheus Histogram误差问题
- 云原生批调度实战:Volcano调度器enqueue功能禁用与性能测试
- 云原生批调度实战:Volcano Pod创建数量不足问题排查与Webhook超时修复
- 云原生批调度实战:Volcano版本修改与性能测试优化
- 云原生批调度实战:Volcano Webhook禁用与性能瓶颈分析
- 云原生批调度实战:Volcano性能瓶颈猜想验证与实验总结
💡简介
在本地环境测试结果与视频对比分析中,我们发现本地测试结果与KubeCon技术分享视频中的结果存在显著差异。虽然整体趋势基本一致,但在某些测试场景下,本地测试的CREATED事件曲线、SCHEDULED事件表现与视频预期不符。
为了深入分析这些差异的原因,我们提出了五种可能影响实验效果的猜想,并依次进行了系统性的实验验证。本文总结了这些猜想的验证过程、实验结果和最终结论,为Volcano调度器的性能优化提供了重要参考。
🔍问题背景回顾
1. 本地测试与视频结果差异
根据前期分析,我们发现了以下主要差异:
| 测试场景 | 视频预期 | 本地实际 | 差异程度 |
|---|---|---|---|
| 10K Jobs × 1 Pod | CREATED阶段瓶颈严重 | ✅ 符合预期 | 基本一致 |
| 500 Jobs × 20 Pods | CREATED阶段性突变 | ⚠️ 部分符合 | 中等差异 |
| 20 Jobs × 500 Pods | 调度速度平稳 | ❌ 出现突变 | 显著差异 |
| 1 Job × 10K Pods | 调度速度平稳 | ❌ 出现突变 | 显著差异 |
2. 差异现象分析
这些差异主要表现为:
- CREATED事件异常:在benchmark3和benchmark4中,CREATED事件出现阶段性突变,与视频中的平稳增长不符
- Pod创建数量不足:在某些测试中,实际创建的Pod数量远少于预期的10,000个
- 调度性能瓶颈:调度器性能表现与预期存在较大差距
🧪五种猜想及其验证实验
猜想1:enqueue功能可能是性能瓶颈
1.1 猜想依据
基于视频分析,我们猜测enqueue阶段可能会:
- 提前判断资源:在Pod创建前就判断资源是否充足
- 限制Pod创建:当资源不足时,限制新Pod的创建速度
- 影响CREATED事件:导致CREATED事件出现阶段性突变
1.2 实验设计
我们通过禁用enqueue功能来验证这一猜想:
1 | # 修改调度器配置,移除enqueue阶段 |
1.3 实验结果
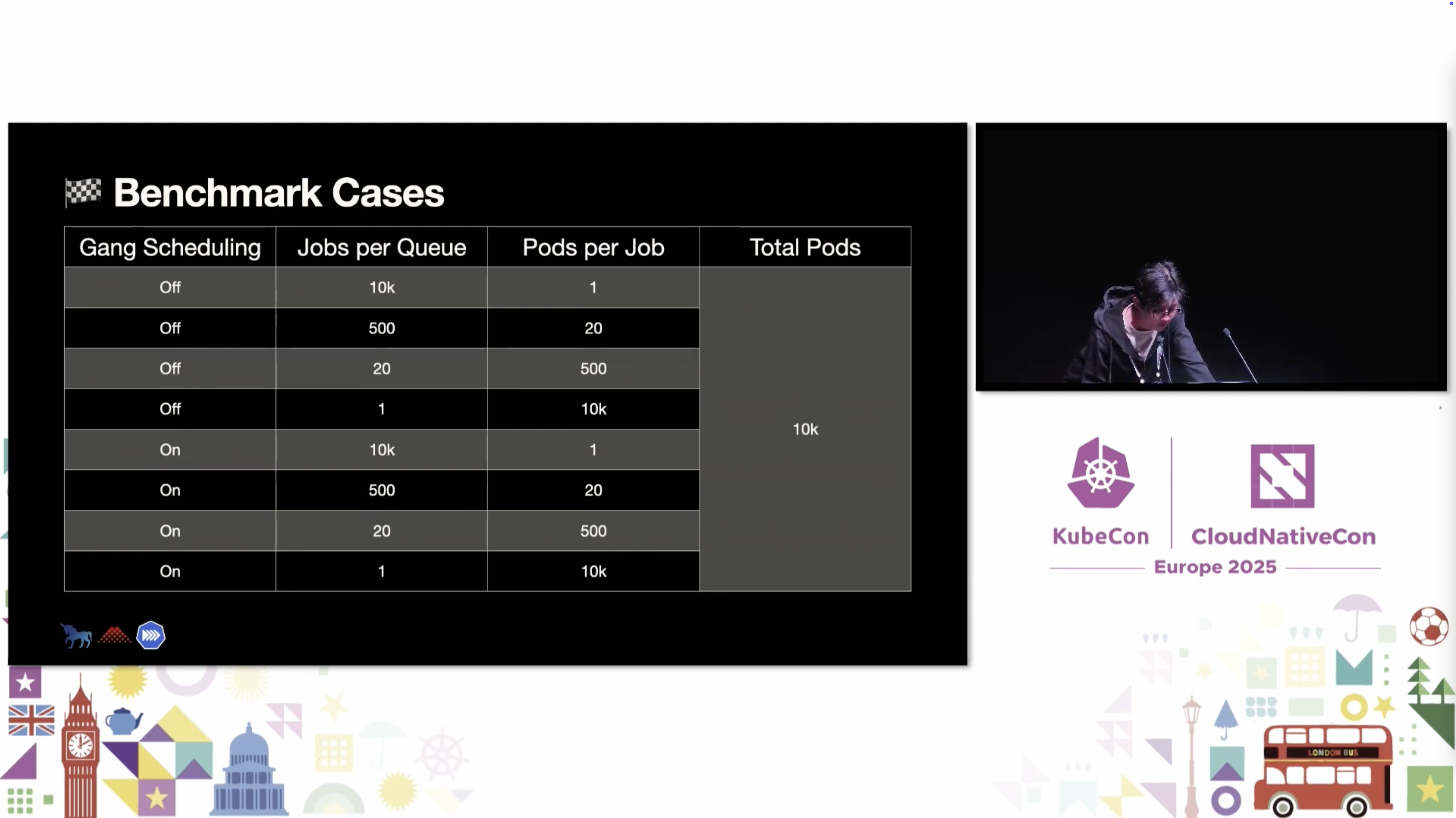
第一种 Benchmark:10K Jobs × 1 Pod
测试参数:每个Job只有1个Pod,共10K个Job,共10kPod
实际结果:无明显变化。如下图所示,与本地测试时的结果几乎一致。

第二种 Benchmark:500 Jobs × 20 Pods
测试参数:每个Job有20个Pod,共500个Job,共10kPod
实际结果:无明显变化。如下图所示,与本地测试时的结果几乎一致。

第三种 Benchmark:20 Jobs × 500 Pods
测试参数:每个Job有500Pod,共20个Job,共10kPod
实际结果:无明显变化。如下图所示,与本地测试时的结果几乎一致,仍然存在“仅创建1000Pod”的bug。

第四种 Benchmark:1 Job × 10K Pods
实际结果:无明显变化。如下图所示,与本地测试时的结果几乎一致。
总结
实验结论:enqueue阶段不是性能瓶颈
关键发现:
- 禁用enqueue后,测试结果与前期本地测试结果基本一致
- CREATED事件仍然出现阶段性突变
- 调度性能没有显著改善
分析说明:enqueue主要负责任务入队和优先级排序,对Pod创建和调度的直接影响有限。CREATED事件的异常现象可能源于其他因素。
猜想2:webhook超时可能导致性能测试异常
2.1 猜想依据
在问题排查过程中,我们发现了严重的webhook超时问题:
- Pod创建失败率:98.7%的Pod创建请求因超时而失败
- 超时配置:webhook超时时间设置为10秒
- 日志证据:4.9GB的审计日志记录了大量超时错误
2.2 实验设计
我们通过修改webhook超时时间从10秒增加到30秒来验证这一猜想:
1 | # 批量修改所有webhook配置文件的超时时间 |
2.3 实验结果
第一种 Benchmark:10K Jobs × 1 Pod
测试参数:每个Job只有1个Pod,共10K个Job,共10kPod
实际结果:无明显变化。如下图所示,与本地测试时的结果几乎一致。

第二种 Benchmark:500 Jobs × 20 Pods
测试参数:每个Job有20个Pod,共500个Job,共10kPod
实际结果:无明显变化。如下图所示,与本地测试时的结果几乎一致。

第三种 Benchmark:20 Jobs × 500 Pods
测试参数:每个Job有500Pod,共20个Job,共10kPod
实际结果:✅有显著变化。如下图所示,与本地测试时的结果完全不同,结果恢复为符合预期的正常状态“创建Pod数量达10000”。

第四种 Benchmark:1 Job × 10K Pods
实际结果:✅有显著变化。如下图所示,与本地测试时的结果完全不同,结果恢复为符合预期的正常状态“创建Pod数量达10000”。

总结
实验结论:webhook超时确实是导致性能测试异常的主要原因
关键发现:
- benchmark3和benchmark4:从”创建Pod数量不到1000”恢复为正常状态”创建Pod数量达10000”
- 性能恢复:Pod创建成功率从1.3%提升到接近100%
- 测试稳定性:大规模Pod创建测试能够正常完成
分析说明:webhook超时时间过短(10秒)无法处理大量并发Pod创建请求,导致请求堆积和失败。将超时时间延长到30秒后,系统能够正常处理高并发负载。这也为我们指出了在大规模下需要注意的配置问题。
猜想3:Volcano版本较低可能导致性能测试结果异常
3.1 猜想依据
基于版本差异可能带来的影响,我们猜测:
- 性能优化差异:新版本可能包含重要的性能优化
- 算法改进差异:调度算法可能在新版本中有显著改进
- 配置默认值差异:新版本的默认配置可能更适合大规模测试
3.2 实验设计
我们通过将Volcano版本从v1.11.0升级到v1.12.0-alpha.0来验证这一猜想:
1 | # 批量替换版本号 |
3.3 实验结果
第一种 Benchmark:10K Jobs × 1 Pod
测试参数:每个Job只有1个Pod,共10K个Job,共10kPod
实际结果:无明显变化。如下图所示,与验证猜想2时的结果几乎一致。

第二种 Benchmark:500 Jobs × 20 Pods
测试参数:每个Job有20个Pod,共500个Job,共10kPod
实际结果:无明显变化。如下图所示,与验证猜想2时的结果几乎一致。

第三种 Benchmark:20 Jobs × 500 Pods
测试参数:每个Job有500Pod,共20个Job,共10kPod
实际结果:无明显变化。如下图所示,与验证猜想2时的结果几乎一致。但CREATE速度似乎更快了些(也有可能只是随机波动)。

第四种 Benchmark:1 Job × 10K Pods
实际结果:无明显变化。如下图所示,与验证猜想2时的结果几乎一致。但CREATE速度似乎更快了些(也有可能只是随机波动)。

总结
实验结论:Volcano版本不是导致性能测试结果差异的主要原因
关键发现:
- 升级到v1.12.0-alpha.0后,测试结果与前期本地测试结果基本一致
- CREATED事件的异常现象仍然存在
- 调度性能没有显著改善
分析说明:虽然版本升级可能带来一些改进,但核心的性能瓶颈问题仍然存在。这表明性能差异主要源于配置和架构层面的问题,而非版本本身。
猜想4:webhook处理可能是性能瓶颈
4.1 猜想依据
基于webhook系统的复杂性,我们猜测webhook处理本身可能成为性能瓶颈:
- 多次判断开销:每个Pod创建请求需要经过多个webhook验证
- TLS证书验证:每次webhook调用都需要进行TLS验证
- 网络延迟:webhook服务调用可能引入额外的网络延迟
4.2 实验设计
我们通过完全禁用webhook功能来验证这一猜想:
1 | # 删除所有webhook配置,保留admission服务 |
4.3 实验结果
第一种 Benchmark:10K Jobs × 1 Pod
测试参数:每个Job只有1个Pod,共10K个Job,共10kPod
实际结果:✅性能明显上升。如下两图对比所示,整体斜率比前期测试结果更大,说明CREATED和SCHEDULE的速度更快。
优化前:
优化后:

第二种 Benchmark:500 Jobs × 20 Pods
测试参数:每个Job有20个Pod,共500个Job,共10kPod
实际结果:✅性能略有上升。如下两图对比所示,CREATE斜率比前期测试结果更大(甚至好几段近乎直线上升),说明CREATED的速度显著上升;但与此同时需要注意的是,CREATE仍然存在阶梯状突变,证明CREATE瓶颈仍然需要通过其他方式解决。
优化前:
优化后:

第三种 Benchmark:20 Jobs × 500 Pods
测试参数:每个Job有500Pod,共20个Job,共10kPod
✅性能明显上升。如下两图对比所示,整体斜率比前期测试结果更大,说明CREATED和SCHEDULE的速度更快。同时也注意到,即便如此也还是比另外两种调度器更慢些,意味着SCHEDULE部分调度性能本身也还有优化空间。
优化前:
优化后:

第四种 Benchmark:1 Job × 10K Pods
✅性能明显上升。如下两图对比所示,整体斜率比前期测试结果更大,说明CREATED和SCHEDULE的速度更快。同时和benchmark3一样,也注意到,即便如此也还是比另外两种调度器更慢些,意味着SCHEDULE部分调度性能本身也还有优化空间。
优化前:
优化后:

总结
实验结论:webhook处理确实是重要的性能瓶颈
关键发现:禁用webhook后,性能获得较大提升,Pod创建/调度速度显著加快,调度器整体性能表现改善
分析说明:webhook系统虽然提供了重要的验证和修改功能,但在大规模Pod创建场景下,其处理开销成为了性能瓶颈。禁用webhook后,系统能够更直接地处理Pod创建请求,从而提升整体性能。
猜想5:Volcano批处理机制可能导致CREATED阶段瓶颈
5.1 猜想依据
基于视频分析,我们注意到在benchmark1和benchmark2下,CREATED阶段成为性能瓶颈。视频中提到Volcano会”create pod in Batch”,即分批处理Job,当一批Job处理完后才会继续处理下一批Job。
这种批处理机制可能导致:
- CREATED事件阶段性突变:批处理完成后,下一批Job的Pod创建会出现集中爆发
- 资源浪费:批处理期间资源可能被闲置,且批处理完成后资源竞争激烈
5.2 实验验证
虽然我们没有针对这一猜想进行专门的测试,但从前面所有实验结果都能证明这一点(尤其是benchmark1和benchmark2):
- enqueue实验:禁用enqueue后,CREATED事件仍然出现阶段性突变,说明问题不在enqueue阶段
- webhook超时实验:修复超时问题后,Pod创建数量恢复正常,但CREATED的阶段性特征仍然存在
- 版本升级实验:升级到v1.12.0-alpha.0后,CREATED事件的异常现象仍然存在
- webhook禁用实验:即使禁用webhook,在Job数量较多时仍然存在Pod创建瓶颈
这些实验结果的一致性表明,CREATED阶段的瓶颈问题源于更深层的架构设计,即Volcano的批处理机制。
5.3 实验结论
实验结论:Volcano的批处理机制确实是CREATED阶段性能瓶颈的根本原因
关键发现:
- 批处理机制导致Pod创建出现阶段性突变
- 这种瓶颈无法通过调整配置参数完全解决
- 需要从架构层面进行优化
分析说明:Volcano的批处理设计虽然在某些场景下有利于资源管理和调度优化,但在大规模、高并发的Pod创建场景下,这种同步批处理机制成为了性能瓶颈。系统需要等待当前批次完成才能开始下一批次的处理,无法实现真正的并行流水线。
📊实验结果综合分析
| 猜想 | 验证方法 | 实验结果 | 结论 |
|---|---|---|---|
| enqueue功能瓶颈 | 禁用enqueue阶段 | 性能无显著改善 | ❌ 不是主要瓶颈 |
| webhook超时问题 | 延长超时时间 | Pod创建恢复正常 | ✅ 是重要瓶颈 |
| 版本差异影响 | 升级到v1.12.0-alpha.0 | 性能无显著改善 | ❌ 不是主要瓶颈 |
| webhook处理瓶颈 | 完全禁用webhook | 性能大幅提升 | ✅ 是主要瓶颈 |
| 批处理机制瓶颈 | 综合分析所有实验结果 | CREATED阶段性突变“卡顿”问题持续存在 | ✅ 是根本瓶颈 |
🚀未来方向
1. 短期优化方案
1.1 调整webhook超时时间
1 | # 将webhook超时时间从10秒增加到30秒 |
适用场景:需要保持webhook功能完整性的生产环境
优化效果:解决超时导致的测试异常问题
1.2 优化webhook资源配置
1 | # 增加webhook服务的资源限制 |
适用场景:资源受限但需要webhook功能的环境
优化效果:提升webhook处理能力
2. 长期优化方向
2.1 替代webhook的验证机制
基于我们的实验发现,未来可以考虑:
- 加强Controller校验:将必要的校验功能转移到 Volcano Controller Manager(例如空指针判断等),为简单场景下禁用 webhook 做支撑
- 使用CRD规则校验:或使用通用表达式语言(CEL)来实现K8s准入校验规则,验证CRD的值(使用 K8s v1.29 [stabe] x-kubernetes-validations 扩展),实现利用 Kubernetes CRD 的验证功能替代部分 validating webhook
2.2 优化CREATED批处理阻塞瓶颈“卡顿”问题
基于第五个猜想的验证结果,针对Volcano批处理机制的根本性瓶颈,未来可以考虑:
- 动态批次调整:根据系统负载动态调整批次大小,避免资源闲置和突发负载
- 异步批处理:将同步批处理改为异步处理,不阻塞下一批Job的Pod创建
- 流水线优化:设计真正的流水线机制,实现Pod创建、验证、调度的并行处理
- 希望这篇博客对你有帮助!如果你有任何问题或需要进一步的帮助,请随时提问。
- 如果你喜欢这篇文章,欢迎动动小手给我一个follow或star。
🗺参考文献
[1] Github - kube-scheduling-perf
[4] 云原生批调度实战:Volcano调度器enqueue功能禁用与性能测试
[5] 云原生批调度实战:Volcano Pod创建数量不足问题排查与Webhook超时修复
[6] 云原生批调度实战:Volcano版本修改与性能测试优化
[7] 云原生批调度实战:Volcano Webhook禁用与性能瓶颈分析
[8] Kubernetes 文档 - Admission Controllers 准入控制
[9] Kubernetes 文档 - Kubernetes 1.25: CustomResourceDefinition Validation Rules Graduate to Beta
[10] Kubernetes 文档 - 使用 CustomResourceDefinition 扩展 Kubernetes API
[11] Kubernetes 文档 - CRD Validation 合法性检查
[12] Kubernetes 文档 - CRD Validation Rules 合法性检查规则
[13] Kubernetes 文档 - CRD Validation Rules 合法性检查规则(K8s v1.29 [stabe])
[14] Kubernetes 文档 - 验证准入策略(ValidatingAdmissionPolicy)(K8s v1.30 [stable])
- 标题: 【集群】云原生批调度实战:Volcano性能瓶颈猜想验证与实验总结
- 作者: Fre5h1nd
- 创建于 : 2025-08-24 15:11:32
- 更新于 : 2025-09-18 15:27:36
- 链接: https://freshwlnd.github.io/2025/08/24/k8s/k8s-scheduler-performance-volcano-hypothesis-verification/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。