
【集群】云原生批调度实战:Volcano 深度解析(四):CREATE 阶段瓶颈追踪与优化思考

本系列《云原生批调度实战:Volcano 深度解析》计划分为以下几篇,点击查看其它内容。
本文承接《Volcano 深度解析(三):核心流程解析与架构设计》,聚焦 CREATED 阶段 的性能瓶颈。实验环境及测试方法延续前文,不再赘述。
0️⃣ 背景回顾
在 Webhook 禁用实验 中,我们已确认:即使禁用 Webhook,CREATED 曲线仍呈阶梯式“突增 / 突停”。

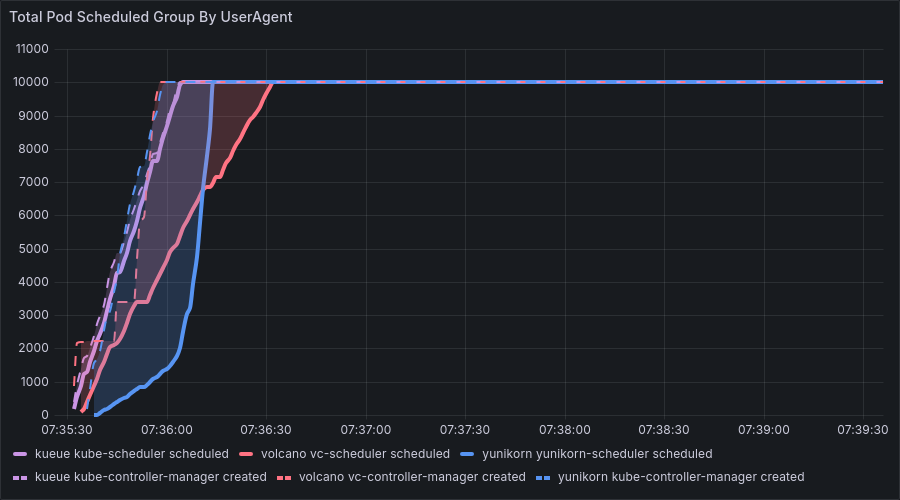
本文尝试回答两个问题:
- 阶梯为何产生?
- 有哪些“调得动”的参数能够缓解?
1️⃣ 实验现象重现
| Benchmark | Job×Pod | 现象 | 备注 |
|---|---|---|---|
| benchmark-1 | 10K×1 | CREATE 与 SCHEDULE 几乎重叠,整体速度四组中最慢 | CREATE = 主要瓶颈 |
| benchmark-2 | 500×20 | 阶梯最清晰,阶段性出现 CREATE 阻塞 → SCHEDULE 停顿 | CREATE & SCHEDULE 交替受阻 |
| benchmark-3 | 20×500 | CREATE 有阶梯但速度明显快于 SCHEDULE | SCHEDULE 成瓶颈 |
| benchmark-4 | 1×10K | 同上,CREATE 不是主瓶颈 |
猜想:JobController 对 Pod 的“批量同步创建”导致单批全部结束前无法进入下一批,从而表现为突停;批量完成后瞬时放量,表现为突增。
2️⃣ 代码走读:JobController 批量创建逻辑
2.1 Worker 协程来源
1 | // cmd/controller-manager/app/server.go:134-139 |
--worker-threads 默认为 50(不指定则使用该值),决定 JobController 并发消费 Job 请求 的 goroutine 数。
⚠️ 注意:这里的协程只决定 Job 并行数,跟 Pod 并行数并非一回事。
2.2 哈希分片与队列
1 | // pkg/controllers/job/job_controller.go:318-333 |
FNV(Fowler–Noll–Vo)是一种速度快、冲突率低的非加密散列函数,它在 Volcano 中承担 一致分片 的角色:
- 单 Job 串行化:保证相同的 JobKey 永远路由到同一 worker,避免多协程并发修改同一 Job 状态导致的竞态(如版本冲突、重复创建 Pod 等)。
- 负载均衡:不同 Job 均匀散落到
workers个队列,提升并行度。
❓ 如果不保证“同一Job → 同一协程”?
- 多协程可能同时进入同一 Job 的状态机,导致 Status 冲突(ResourceVersion 不匹配重试、乐观锁失败)。
- 重复创建 Pod / PodGroup,产生 资源泄漏 与 Gang 调度失败。
- 如不使用该机制,则需要加全局锁或精细乐观重试,得不偿失。
3️⃣ CREATE 批量创建流程
PodGroup 创建
1 | // pkg/controllers/job/job_controller_actions.go:190-214 |
一次 API 调用即可完成,且一个 Job 只建一个 PodGroup;创建本身比较简单(仅是逻辑单元),可能不是主要瓶颈:
- PodGroup 本质是一个 CRD 对象(仅几十字节的 Spec & Metadata,见
pkg/controllers/job/job_controller_actions.go定义部分),创建过程只是 kube-apiserver → etcd 的一次写操作。 - 不涉及调度决策、节点通信或资源计算;成功后即可返回,无后续长耗时流程。
但需注意:若 MinMember 设置过大或 Queue 资源不足,调度器在 后续阶段 仍可能因 PodGroup 不满足条件而阻塞 Job 启动,这属于调度环节而非 CREATE 环节。
Pod 创建
1 | // pkg/controllers/job/job_controller_actions.go |
观察:每个 Job 中的所有 Pod 都必须在同一批完成,
Wait()阻塞期间该 worker 协程无法服务其他 Job,形成“突停”。
与上述PodGroup有所差异,由于Pod是K8s原生对象,涉及到的字段极多且复杂,既需要默认填充大量字段、也需要花更多时间写入etcd,因此更容易成为瓶颈。
4️⃣ CREATE 阶段可能的瓶颈链路
- ControllerManager – PodGroup 创建:单请求,理论影响小;仅在 CRD 校验或 etcd 压力大时显现。
- ControllerManager – Pod 创建并发:瞬时并发高且字段复杂,容易受 kube-apiserver QPS/TPS 限流影响。
- kube-apiserver – etcd 写入:大批量对象持久化;etcd IOPS 饱和时延长请求时长。
- 网络 / TLS 握手:每 Pod 一次 HTTPS;高并发下握手耗时占比提升。
- Webhook(若开启):Mutating/Validating 延时或超时。
- Worker 协程饱和:
--worker-threads阈值被占满后,新 Job 无法 dequeue,外部观察即“突停”。
在四组 Benchmark 中,总 Pod 数一致(10K),但 Job 数量越多,Worker 越容易饱和,因此出现瓶颈的并非 “单 Job 内 Pod 数” 而是 “Cluster 同时活跃的 Job 数”。
5️⃣ 关键对象关系
| 对象 | 层级 | 作用 | 与其他对象关系 |
|---|---|---|---|
| Job | Volcano CRD | 用户提交的批处理作业 | 一个 Job 拥有 1 PodGroup & N Tasks |
| PodGroup | Volcano CRD | Gang 调度边界,决定最小可运行成员数 | Job 创建时同步生成;Scheduler 以 PG 维度做满足性判断 |
| Task | Job 内部元素 | Job 的逻辑分片,可用不同镜像/参数 | Task 生成 多个 Pod(Replicas) |
| Pod | K8s 原生 | 实际运行单元 | 由 Task 模板实例化,归属同一 PodGroup |
PodGroup ≠ Task:个人理解前者是 Job 的化身,后者是 Job 内的子对象。
层级关系为:1 Job(PodGroup) → n Task → n*m Pod。
6️⃣ 相关参数与理论影响
| 参数 | 默认 | 预期影响 | 实测结论 |
|---|---|---|---|
--worker-threads | 50 | 决定可同时被处理的 Job 数 | ✅ 提高可缩短突停时长,但系统整体压力增大 |
task.replicas | 用户输入 | 决定单 Job 内批量大小 | ⚠️ 非根因;更改只影响单 batch 时长 |
| 新增参数 | N/A | 控制每次并发 Pod 数(而非局限于一个 Job 内的 Pod 数) | 🚧 需进一步设计 |
结论:
- Job 数 → Worker 饱和度 → 是否突停。
- Replica 数 → 单 worker 持续时间 → 阶梯宽度。
7️⃣ 优化方向
| 方向 | 复杂度 | 收益 | 说明 |
|---|---|---|---|
智能调整 --worker-threads | 低 | 高 | 观察到出现瓶颈(或观察到 replicas 普遍较小)时,自动提高并行协程数,削弱同步阻塞 |
| 引入新参数,或调整协程Wait阻塞逻辑 | 中 | 高 | 分片提交 Pods(支持跨Job并行),削弱同步阻塞 |
- 希望这篇博客对你有帮助!如果你有任何问题或需要进一步的帮助,请随时提问。
- 如果你喜欢这篇文章,欢迎动动小手给我一个follow或star。
🗺参考文献
- 标题: 【集群】云原生批调度实战:Volcano 深度解析(四):CREATE 阶段瓶颈追踪与优化思考
- 作者: Fre5h1nd
- 创建于 : 2025-08-26 19:45:21
- 更新于 : 2025-09-05 09:47:02
- 链接: https://freshwlnd.github.io/2025/08/26/k8s/k8s-volcano-create-analysis/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。