【论文】略读笔记90-前沿-可扩展 MoE 训练

📖《X-MoE: Enabling Scalable Training for Emerging Mixture-of-Experts Architectures on HPC Platforms》
2025 年 University of Illinois Urbana-Champaign(伊利诺伊大学厄巴纳-香槟分校)、Oak Ridge National Laboratory(橡树岭国家实验室,ORNL) 团队发表于 CCF-A 类会议 SC(International Conference for High Performance Computing, Networking, Storage and Analysis)。
🎯需求
- 以 DeepSeek-MoE 为代表的新兴专家专用 MoE 架构(expert-specialized MoE),通过更细粒度的专家划分和更大的 top-k 路由(top-k routing)获得了更强的模型质量。
- 大语言模型(LLM)已成为现代人工智能应用的支柱,在对话系统、代码生成和科学推理等领域取得了显著的成果。
- 然而,大规模训练这些模型仍然非常昂贵。例如,GPT-3 或 GPT-4 规模的训练模型会消耗数十万个 GPU 天,并产生数十亿美元的计算成本。因此,在保持高模型质量的同时降低训练成本已成为一个关键的研究挑战。
- 为了提高 LLM 的训练效率,人们做出了许多努力。其中,专家混合模型(MoE)已成为一种很有前途的方法,它可以对模型参数进行亚线性计算,从而在不增加训练成本的情况下提高模型质量。
- 与密集模型相比,MoEs 可以稀疏地激活模型参数,从而可以扩展到更大的模型参数,同时保持相对较低的计算预算。之前的研究表明,MoEs 可以成功扩展到数万亿个参数。
- 最近,DeepSeek-MoE 等模型代表了一类新兴的 MoE 架构,它们不同于 GShard 和 Mixtral-MoE 等早期设计。这些模型依赖于细粒度专家和大 top-k 路由(large top-k routing)等架构修改,以允许专家专注于更独特的上下文概念,即所谓的专家专业化(expert specialization)。因此,DeepSeek-MoE 风格模型在以低成本加速 LLM 训练方面具有巨大潜力,重新激发了人们为新兴 MoE 架构开发可扩展高效训练系统的兴趣。
🚧现状
- 遗憾的是,大规模训练专家专用 MoE 非常具有挑战性。
- 这类架构的可扩展性受到三类系统瓶颈限制:一是过度依赖英伟达平台,二是显著的激活内存(activation memory)开销,三是代价较高的全对全通信(all-to-all communication)。
- 首先,现有的 MoE 训练系统严重依赖于针对标准 MoE 的 CUDA 特定实现,这对于专家专业化 MoE 来说效率低下,而且难以移植到非英伟达平台,如 AMD Instinct GPU 或使用 ROCm 和 RCCL 的基于 Slingshot 的互连。
- 这种跨平台支持的缺失导致内存使用率过高,在 Frontier 和 Aurora 等异构高性能计算系统上表现不佳(第 3.1 节)。
- 我们的分析表明,根据传统 MoE 和英伟达平台假设设计的现成 MoE 训练系统,在新的 MoE 架构和非英伟达硬件上的表现并不理想。
- 例如,我们发现 Tutel 和 DeepSpeed-MoE 等最先进的 MoE 框架在 AMD MI250X GPU 上的性能小于 10 TFLOPS,不到其峰值性能的 10%,而 MegaBlocks 则与英伟达 Megatron-LM 高度集成,难以在 AMD 硬件上运行。
- 其次,专家专业化的 MoE 引入了结构转变:它们增加了每个 token 的路由专家数量,并缩小了每个专家的隐藏维度。
- 这种变化将内存瓶颈从模型参数转移到了激活,尤其是在调度和组合阶段。
- 然而,现有的 MoE 训练系统,如 DeepSpeed-MoE、DeepSpeed-TED 和 Tutel,并不能有效解决这一瓶颈转移问题,导致内存爆炸(第 3.2 节)。
- 第三,多专家路由大大增加了通信的重复性,尤其是当每个 token 选择多个专家时。
- 在具有分层互连的平台上,如 Frontier 中的 Dragonfly 网络,这会导致节点间带宽的低效利用,并随着专家粒度的增加而使通信成为训练效率的主要瓶颈(第 3.3 节)。
🛩创新
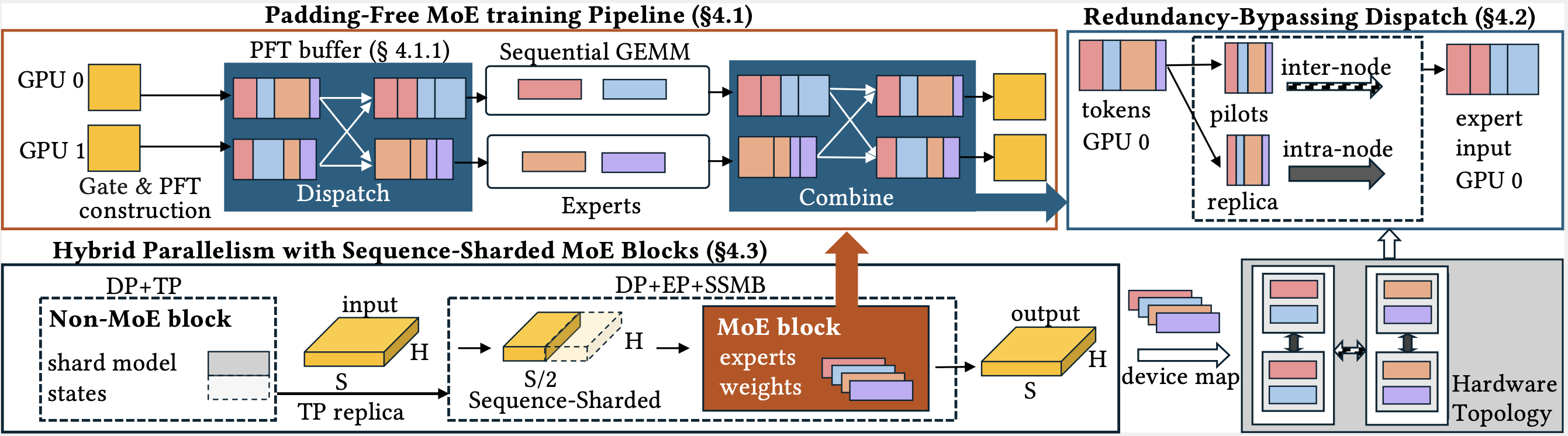
- 在这项工作中,我们提出了在跨平台、非英伟达硬件上训练新兴 MoE 架构的系统级优化方案 X-MoE,这是一个面向下一代 MoE 架构的训练系统,目标是在 HPC 平台上提供可扩展的训练性能。
- 它包含几类系统技术:无填充 MoE 训练(padding-free MoE training)与跨平台内核(cross-platform kernels)以提高内存和通信效率、冗余绕过调度(redundancy-bypassing dispatch)以减少通信,以及带序列分片 MoE 块(sequence-sharded MoE blocks)的混合并行(hybrid parallelism)。
- 与之前的系统不同,我们不依赖 CUDA 等供应商特定的软件栈,而是依赖 Triton 等可移植后端。这使得 X-MoE 与后端无关,适用于未来的硬件平台。
- 据我们所知,X-MoE 是首个针对新兴的专家专用 MoE 和非英伟达平台的异构性进行系统优化的研究成果。
📊效果
- 我们在 Frontier 超级计算机上演示了我们的方法,该超级计算机由采用 Dragonfly 架构的 AMD MI250X GPU 组成。
- X-MoE 能够在 1024 个 AMD GPU 上训练多达 545B 参数的 DeepSeek 风格 MoE,这比使用现有解决方案在相同硬件预算下训练的最大模型大 10 倍。
- 除模型规模外,X-MoE 的训练吞吐量比最先进的 MoE 系统高出 1.42 倍,同时在弱扩展和强扩展方面都优于它们。
- 为了提高可用性,X-MoE 已与 DeepSpeed(一个流行的开源 DL 训练库)集成,使其可用于未来的 MoE 训练工作负载。
⛳️未来机会
- 大规模 all-to-all 通信在 512 到 1024 GPU 时出现更多长尾和跨机架敏感性,后续可以进一步研究面向硬件拓扑和并发作业干扰的 MoE 通信调度。
- 专家并行 / 数据并行放置策略(EP / DP placement)会随模型大小和硬件拓扑变化,后续可以把这种放置选择做成自动规划器,而不是依赖人工规则。
🧠疑问
- 看起来是非常扎实的工作,尤其在工程实践上已经有了很强的产出和丰富的实验。但在摘要中故事线梳理得不是特别清楚,且摘要中主要是提出问题、所提出的解决方案并没有对照着“激活值”和“全对全通信(all-to-all communication)”来说明如何解决而是简单罗列。还需要进一步阅读才能明确其解决方案。
- 希望这篇博客对你有帮助!如果你有任何问题或需要进一步的帮助,请随时提问。
- 如果你喜欢这篇文章,欢迎动动小手给我一个follow或star。
🗺参考文献
[1] Yueming Yuan, Ahan Gupta, Jianping Li, Sajal Dash, Feiyi Wang, and Minjia Zhang. 2025. X-MoE: Enabling Scalable Training for Emerging Mixture-of-Experts Architectures on HPC Platforms. arXiv:2508.13337.
[2] X-MoE Project Page
[3] X-MoE Code
- 标题: 【论文】略读笔记90-前沿-可扩展 MoE 训练
- 作者: Fre5h1nd
- 创建于 : 2026-05-14 12:35:54
- 更新于 : 2026-05-14 13:55:36
- 链接: https://freshwlnd.github.io/2026/05/14/literature/literatureNotes90/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。



评论